接下来几天将复习Graphical Model的一系列模型。今天先复习一下EM算法。
Graphical Model和Latent Variable
首先,我们了解一下graphical model的技术思路:
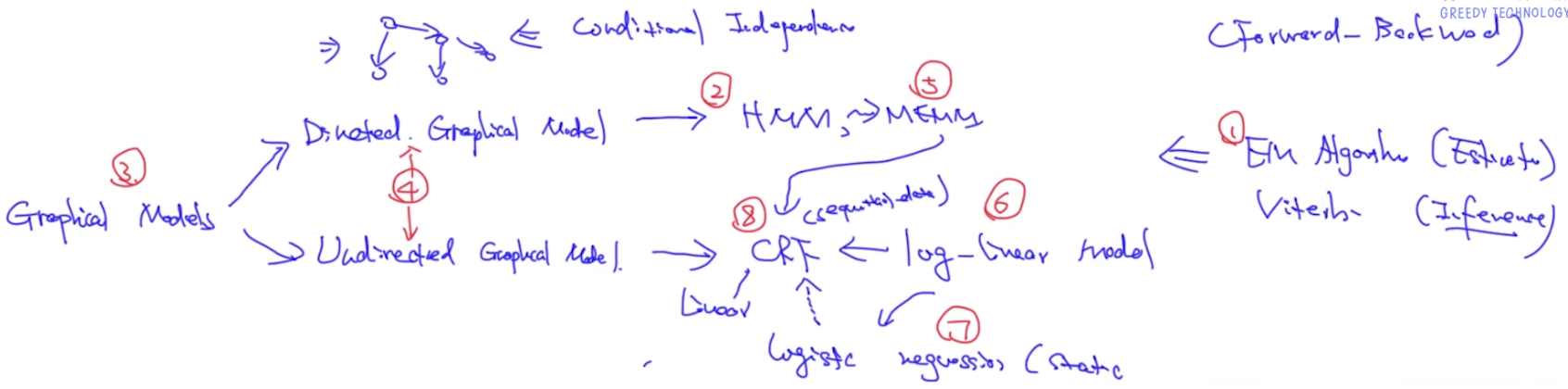
从上图中可以看到,Graphical Model可以分成两类,一类是有向图,典型代表是HMM;一类是无向图,典型代表是CRF。当我们能找出状态之间的依赖关系时,可以使用HMM,因为HMM可以利用conditional independence条件独立性质;当我们刻画不出依赖关系时,可以使用CRF。其中,从HMM可以推导出MEMM模型,从MEMM可以推导出CRF模型。我们通常使用的CRF是Linear CRF,其中的Linear是从Log Linear Model中得来的。Log Linear Model可推出的另外一个模型是logistic regressioin,区别是逻辑回归针对static data,CRF针对sequencial data。整个Graphical Model的参数估计使用的是EM算法,推理使用Viterbi算法。
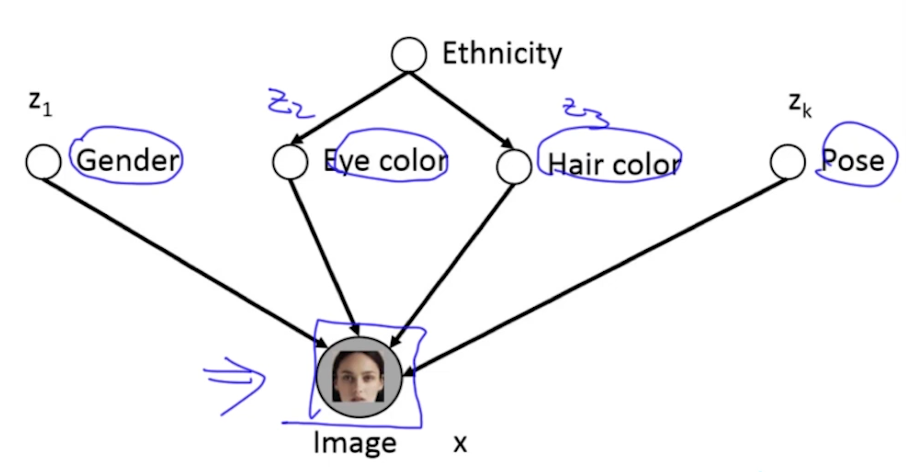
在有隐含变量(latent variable)的模型中,我们经常使用EM算法。那什么是latent variable呢?一个Latent variable model可以用z~x表示,意思是用看不见的z去生成看得见的x。以下图为例,假设任务是生成人脸,那么隐含变量就包含性别、眼睛颜色、头发颜色等信息:
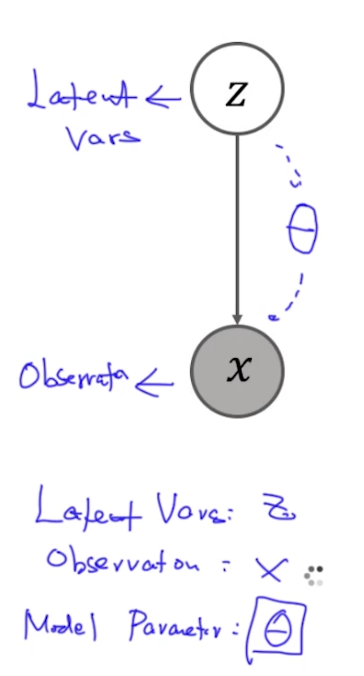
EM的核心是计算参数theta,如下图:
在计算时分为两种情况:
- Complete case:(z, x)都是可观测的,如逻辑回归(已知x预测$\theta$),一般使用MLE
- Imcomplete case:x是可观测的,z是不可观测的,使用EM style算法
MLE for Complete and Imcomplete Case
下面我们来看一下MLE的求解思路。MLE的核心思想是求解$argmax_{\theta}(D|\theta)$,也就是求最大化D情况下的theta值。比如在逻辑回归中就是求解$argmax_{\theta}P({x_i, y_i}_{i=1}^n|\theta)$。而在graphic model中变为$argmax_{\theta}P({x, z|\theta})$。在Complete Case和Incomplete Case中MLE可以分别继续写成如下形式(可以看到$logp(z|\theta_z)$是典型的MLE,我们可以通过数据统计反推出theta值):
【注】:在图模型中联合概率很难表示,有几个技巧可以尝试:
(1)使用conditional independence对形如$P(a,b,c,d,e|\theta)$进行转换:例如n-gram语言模型P(I hate ad|y=垃圾),在朴素贝叶斯中就会近似为P(I|y=垃圾)P(hate|y=垃圾)P(ad|y=垃圾)
(2)使用D-seperation或Markov Blanket对形如$P(a|b,c,d,e,f)$进行转换:比如发现d、e、f对a没有影响,转换为P(a|b,c),进而再转化为函数形式f(\theta),再使用优化方法找出解或者近似解
(3)在Incomplete Case中,由于z也是未知的,所以把z边缘化了
(4)上面图中$p(z|\theta)$和$p(x|z, \theta)$也可以认为是两个函数$f(\theta)和g(\theta)$,也可以使用优化算法进行求解。对于Incomplete Case,$f(\theta)和g(\theta)$很难求解,所以使用EM-style算法求解
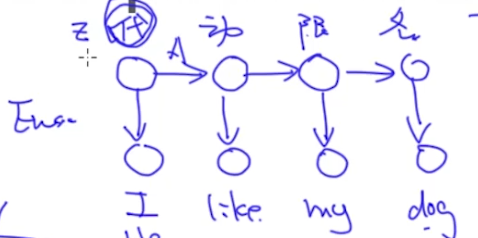
在Complete Case中基本是通过统计方式计算的,以下图为例(假设观测到的是单词,隐变量是词性,建立一个HMM模型,我们可以统计词性之间的Transition Probabilty和词性到单词的Emition Probability):
EM Derivation
EM中一共有3类变量:
- $\theta$: model parameter
- $z$: latent variable
- $x$: obversation
目标:用MLE最大化$L(\theta)=logP(x|\theta)$,也就是求解$argmax_{\theta}L(\theta)=argmax_{\theta}logP(x|\theta)$。
假设:使用iterative算法,已经求解出$\theta_1$,$\theta_2$, …, $\theta_n$,则如何计算$\theta_{n+1}$?
已知:$\theta_n$是对应于$L(\theta_n)$的解,那么$\theta_{n+1}$就是使得$argmax_{\theta}L(\theta) - argmax_{\theta_{n+1}}L(\theta_{n+1})$最大的值(可以理解为使得目标函数提升最大的值),且$argmax_{\theta}L(\theta) - argmax_{\theta_{n+1}}L(\theta_{n+1}) = logP(x|\theta) - logP(x|\theta_n)$,上面思考过程来源于下图:

从上面图中看到,当我们已经优化到log sum的形式时,就很难继续求解了。所以我们想到用一个不等式去近似它。这个不等式就叫做Jensen’s Inequality: (【注】: Jensen’s Inequality可以从凸函数的性质得出来)
(【注】: Jensen’s Inequality可以从凸函数的性质得出来)
经过Jensen’s neuqlity简化,上图中式子可推导成:

继续推导可以得到下图(第6行是由于是常量所以消去了):
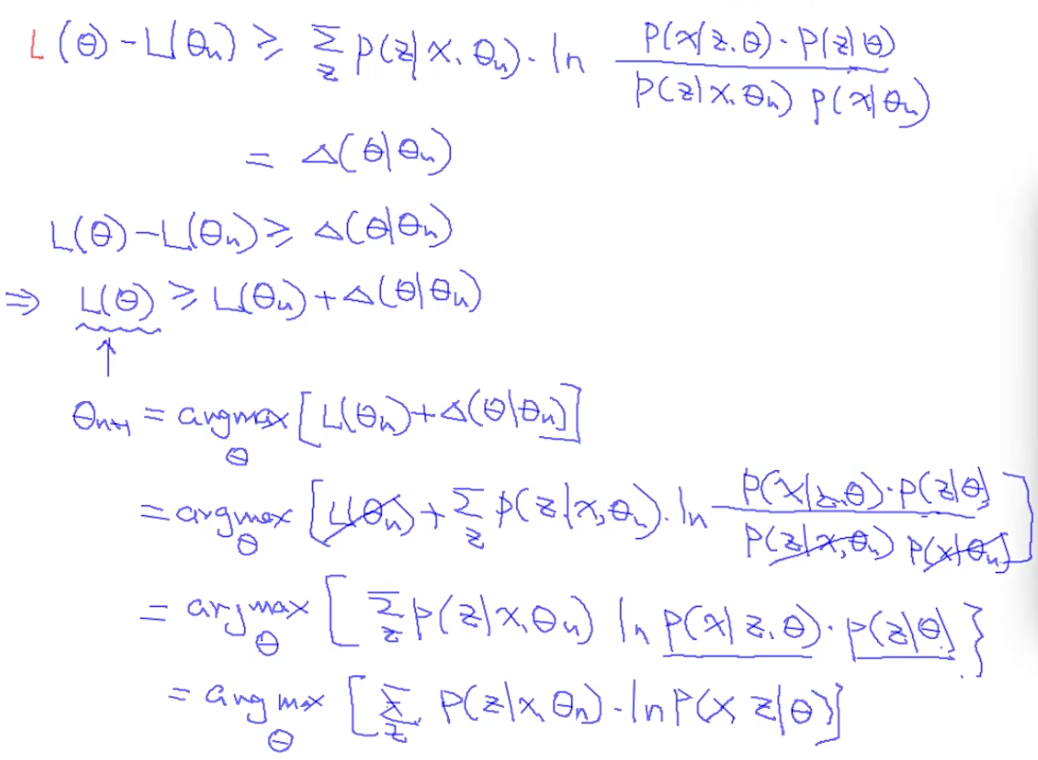
我们可以把最后一项写成Expectation的形式,怎么理解呢?$P(z|x, \theta_n)$是所有可能的z的一个概率分布,我们把每一个可能的z带入到$logP(x, z|\theta)$中,我们就可以计算$logP(x, z|\theta)$的 一个平均值,也就是期望值。由于已知$x$、$\theta_n$,我们可以求出z的期望值。那么对于$logP(x,z|\theta)$来说,由于$x$、$z$、$\theta_n$都是已知的,想求解最大似然,就变成了一个complete case,我们可以通过MLE求解使其最大的$\theta$。
【注】:你可能想问,已知$x$, $\theta_n$,是怎么求出$P(z|x, \theta_n)$的呢?在具体问题中,我们通常会把$P(z|x, \theta_n)$写成一个函数的形式,自然就可以求出来了
EM算法其实就是两个步骤的一个循环,已知$x$, $\theta$求$z$的期望,再用这个$z$求解$\theta$,再去迭代得求解$z$,如下图:
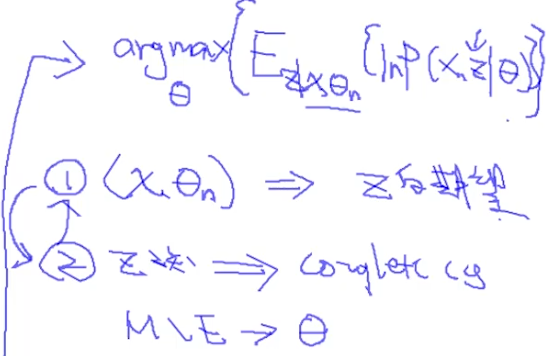
EM算法一定是收敛的,它本质上是coordinate descent,即按照坐标轴去优化。
K-means
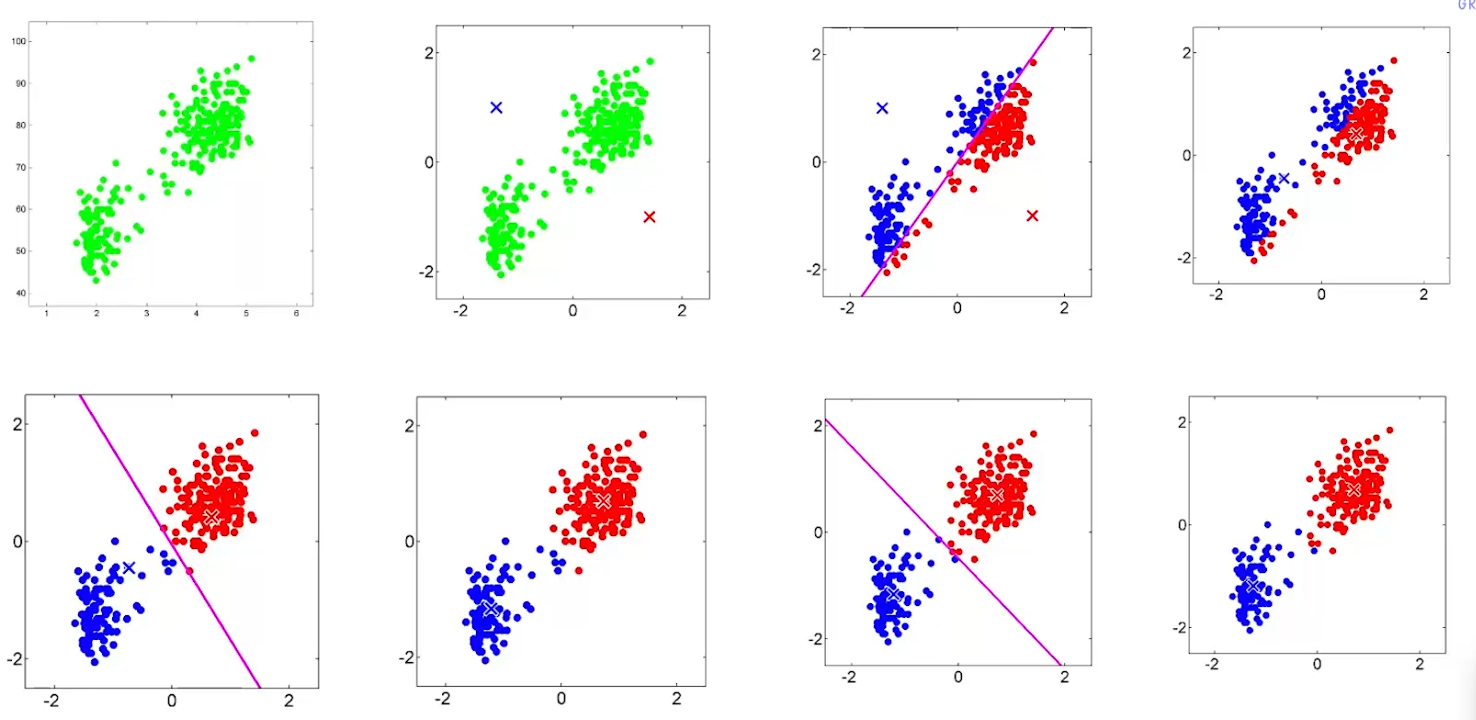
K-means整体上就是选中心点—>根据与中心点的举例聚类—>重新计算中心点,这样一个迭代的过程,如下图所示:
Cost Function
Kmeans的代价函数如下图:

可以看到有两个参数:
- $\mu_k$表示中心点,可以看成是模型参数
- $\gamma_{ik}$表示对$\mu_k$的选择,可以看成是隐变量
K-means和EM的关系
K-means的迭代过程就是先选择$\mu_k$,再计算$\gamma_{ik}$,再根据聚成的簇重新选择$\mu_k$。但K-means是一个EM-style的算法,而不是一个严格意义的EM。因为在EM中,要计算的是隐变量的期望值,即对于$\gamma_{ik}$表示$x_i$属于第$k$个cluster的概率,则$\gamma_{i0}=0.8$, $\gamma_{i1}=0.2$….(有点像GMM哈)。但在K-means中,我们直接令$\gamma_{i0}=1$了。因此Kmeans也叫Hard-Clustering,GMM也叫Soft-Clustering。如下图:
