当我们有大量平行语料,通过什么方法能快速构建出一个词典呢?今天讲的就是基于这个需求所调研的一些方法总结。基本方法有3种:基于统计、基于词对齐、基于词向量。由于基于词对齐比较好理解,就是使用IBM Model进行词对齐后,将translation table拿出来就可以作为一个词表,因此本文不对此进行介绍。本文重点说明另外两种方法:基于统计和基于词向量方法。
基于统计的方法
参考论文:word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs
https://zhuanlan.zhihu.com/p/45730674
https://papers.nips.cc/paper/5477-neural-word-embedding-as-implicit-matrix-factorization.pdf
https://cloud.tencent.com/developer/article/1436217
这篇论文的思想很简单,就是从translation pair共现的角度在平行语料库中挖掘出符合条件的pair。因此,算法首先找到跟每一个source word共现过的target word,其次使用下面三种方法对target word与source word的相关度进行重新排序,最终取前n名作为source word的释义:
- 共现次数:$p(y | x)=\frac{p(x, y)}{p(x)} \approx \frac{c(x, y)}{c(x)} \propto c(x, y)$
互信息:$\begin{aligned}
\operatorname{PMl}(x, y) &=\log \frac{p(x, y)}{p(x) p(y)} \\
& \approx \log \frac{c(x, y)}{c(x) c(y)} \propto \log c(x, y)-\log c(y)
\end{aligned}$Controlled Predictive Effects(CPE):$\begin{aligned}
\operatorname{CPE}(y | x) &=p(y | x)-\sum_{x^{\prime} \in \mathcal{X}} p\left(y | x^{\prime}\right) p\left(x^{\prime} | x\right) \\
&=\sum_{x^{\prime} \in \mathcal{X}} \operatorname{CPE}_{y | x}\left(x^{\prime}\right) p\left(x^{\prime} | x\right)
\end{aligned}$
互信息
PMI是NLP中的一个重要指标,在本文中它可以用来阻止一些stop word有较高的得分。互信息是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
设两个随机变量$(X,Y)$的联合分布为$p(x, y)$,边缘分布分别为$p(x),p(y)$ ,互信息$I(X;Y)$是联合分布$p(x,y)$与边缘分布$p(x)p(y)$的相对熵,即$I(X ; Y)=\sum_{x \in X} \sum_{y \in Y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)}$
上面的$I(X;Y)$其实是可以推导出来的。根据熵的连锁规则,有$H(X, Y)=H(X)+H(Y | X)=H(Y)+H(X | Y)$。因此,$H(X)-H(X | Y)=H(Y)-H(Y | X)$
这个差叫做X和Y的互信息,记作I(X;Y)。按照熵的定义展开可以得到:$\begin{aligned}
I(X ; Y) &=H(X)-H(X | Y) \\
&=H(X)+H(Y)-H(X, Y) \\
&=\sum_{X} p(x) \log \frac{1}{p(x)}+\sum_{y} p(y) \log \frac{1}{p(y)}-\sum_{x, y} p(x, y) \log \frac{1}{p(x, y)} \\
&=\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)}
\end{aligned}$
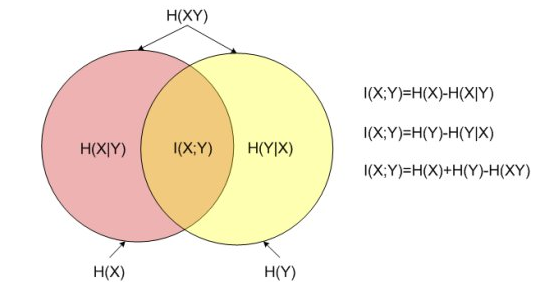
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。
互信息是 X 和 Y 联合分布相对于假定 X 和 Y 独立情况下的联合分布之间的内在依赖性。于是互信息以下面方式度量依赖性:I(X; Y) = 0 当且仅当 X 和 Y 为独立随机变量。从一个方向很容易看出:当 X 和 Y 独立时,$p(x,y) = p(x) p(y)$,因此:$\log \left(\frac{p(x, y)}{p(x) p(y)}\right)=\log 1=0$
可见,互信息是非负的($I(X;Y) ≥ 0$),且是对称的(即 $I(X;Y) = I(Y;X)$)。
其实从PMI角度,可以将skip-gram word2vec模型看成是对一个shifted PMI matrix的矩阵分解的结果,同时PMI和TF-IDF的原理也十分接近。下面我们介绍一篇论文,来从PMI角度理解word2vec,这篇论文为Neural Word Embedding as Implicit Matrix Factorization,其原文在https://papers.nips.cc/paper/5477-neural-word-embedding-as-implicit-matrix-factorization.pdf中。
这篇文章认为,word2vec本质上是对一个word-context相关度的PMI矩阵进行分解。我们可以把word-context看成一个row为word,column为context的矩阵。首先我们定义一些变量:
- word: $w \in V_{W}$
- context: $c \in V_{C}$
- $w_i$的context为其窗口长度为L的附近的词:$w_{i-L}, \ldots, w_{i-1}, w_{i+1}, \ldots, w_{i+L}$
- word vocabulary: $V_w$
- context vocabulary: $V_c$
- word和context的pair集合:$D$
- (w, c)在D中出现的次数:$c(w,c)$
- w在D中出现的次数:$c(w)=\sum_{c^{\prime} \in V_{C}} c\left(w, c^{\prime}\right)$
- c在D中出现的次数:$c(c)=\sum_{w^{\prime} \in V_{W}} c\left(w^{\prime}, c\right)$
- 每个词w可以表示成向量:$\vec{w} \in \mathbb{R}^{d}$,有时用$\left|V_{W}\right| \times d$的矩阵W表示,其中$W_i$表示第$i$个word的表示
- 每个context c可以表示成向量:$\vec{c} \in \mathbb{R}^{d}$,有时用$\left|V_{C}\right| \times d$ 的矩阵C表示,这里的d表示embedding的维度,其中$C_i$表示第$i$个context的表示
- (w, c)属于D的概率:$P(D=1 | w, c)$
其次,我们要建立目标函数。假设有一个(w, c)对,我们如何知道它是否属于D呢?我们使用sigmoid建模这个概率:$P(D=1 | w, c)=\sigma(\vec{w} \cdot \vec{c})=\frac{1}{1+e^{-\vec{w} \cdot \vec{c}}}$,其中的$\vec{w}$和$\vec{c}$就是我们要学习的参数。
所谓的负采样,就是对于在$D$中的$(w,c)$要最大化$P(D=1|w,c)$,而对于不再$D$中的$(w,c)$要最大化$P(D=0|w,c)$。因此目标函数可以写成:$\log \sigma(\vec{w} \cdot \vec{c})+k \cdot \mathbb{E}_{c_{N} \sim P_{D}}\left[\log \sigma\left(-\vec{w} \cdot \vec{c}_{N}\right)\right]$,其中$k$是负采样的个数,$c_N$是使用均匀分布$P_{D}(c)=\frac{c(c)}{|D|}$随机采样的context。
通常我们会使用SGD求解,全局的目标函数定义为:$\ell=\sum_{w \in V_{W}} \sum_{c \in V_{C}} c(w, c)\left(\log \sigma(\vec{w} \cdot \vec{c})+k \cdot \mathbb{E}_{c_{N} \sim P_{D}}\left[\log \sigma\left(-\vec{w} \cdot \vec{c}_{N}\right)\right]\right)$。这样的建模会使得出现在相同context的word有相近的embedding。
那么这个问题是如何跟矩阵分解联系上的呢?在论文中有详细的推导过程,这里我们直接写出结论。当满足下述条件时,函数$l$达到最值:$w \cdot c=\log \left(\frac{c(w, c) \cdot|D|}{c(w) \cdot c(c)}\right)-\log (k)$。其中$D$是训练文本,$c$是词$w$的上下文,$c(w, c)$ 是$(w,c)$ 在$D$中出现的次数, $c(w)$ 和$c(c)$ 以此类推。$\log \left(\frac{c(w, c) \cdot|D|}{c(w) \cdot c(c)}\right)$ 就是$(w,c)$ 的pointwise mutual information(简称PMI),即$M_{i j}^{S G N S}=w_{i} \cdot c_{j}=P M I\left(w_{i}, c_{j}\right)-\log (k)$
由此,我们找到了矩阵$M$ ,而这个$M$就是我们刚才说的shifted PMI。其他一些词向量表示,也可以由相似的推导过程得出。比如对于noise-contrastive estimation,计算的是(shifted) log-conditional-probability matrix:$M_{i j}^{\mathrm{NCE}}=\vec{w}_{i} \cdot \vec{c}_{j}=\log \left(\frac{c(w, c)}{c(c)}\right)-\log k=\log P(w | c)-\log k$
【题外话】:早期的word2vec也有基于词-词共现矩阵的方法,使用LSA将从corpus中统计的word-word共现矩阵进行分解。共现矩阵里的值有时用PMI替代:$P M I\left(w_{i}, w_{j}\right)=\log \frac{p\left(w_{i}, w_{j}\right)}{p\left(w_{i}\right) p\left(w_{j}\right)}=\log \frac{c\left(w_{i}, w_{j}\right) \cdot|\mathcal{C}|}{c\left(w_{i}\right) \cdot c\left(w_{j}\right)}$。使用SVD对矩阵分解得到:$\mathbf{P}=\mathbf{U} \Psi \mathbf{V}^{\top}$,那么当我们想得到K维的,就可以计算:$\mathbf{X}=\mathbf{U}_{k} \mathbf{\Psi}_{k}$。
另外,关于句子、词语、句子-词语之间相似性的计算,推荐参考这篇文章:https://cloud.tencent.com/developer/article/1436217
CPE
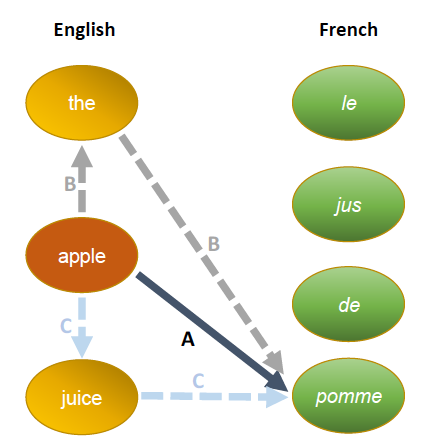
如下图所示,对目标端词pomme,我们如何区分出the、apple、juice哪个对于pomme更重要呢?这时就有了CPE排序。
通过引入修正量$p(y|x’)$、$p(x|x’)$来建模CPE:$\begin{aligned}
\operatorname{CPE}(y | x) &=p(y | x)-\sum_{x^{\prime} \in \mathcal{X}} p\left(y | x^{\prime}\right) p\left(x^{\prime} | x\right) \\
&=\sum_{x^{\prime} \in \mathcal{X}} \operatorname{CPE}_{y | x}\left(x^{\prime}\right) p\left(x^{\prime} | x\right)
\end{aligned}$
其中的x’表示confounder words,对应于上图x=apple,则x’=the 或 juice。上式中CPE项可进一步写成$\mathrm{CPE}_{y | x}\left(x^{\prime}\right)=p\left(y | x, x^{\prime}\right)-p\left(y | x^{\prime}\right)$。CPE可以表达出对于x->y这个词翻译来说,当我们看到一个comfounder word x’时,会对x->y的概率产生多大的影响。如果这个值为0,当我们观察到x’时,发现x和y不相关了。
对于一个词x,我们需要计算所有其CPE_{y|x}(x’)的边缘概率,这在实际中计算量非常大。因此在实际计算中,我们只对top 5000的x进行修正。
源码解读
get_trans_co
get_trans_co用于获取x->y共现最多的pair,传入参数x2ys已计算好x->y的共现次数。
1 | def get_trans_co(x2ys, n_trans): |
get_trans_pmi
get_trans_pmi用于对x的所有translation y进行pmi排序。
1 | def get_trans_pmi(x2ys, x2cnt, y2cnt, Nxy, Nx, Ny, width, n_trans): |
rerank
rerank用于对x的所有translation y进行cpe排序。
1 | def rerank(x2ys, x2cnt, x2xs, width, n_trans): |
rerank_mp
rerank_mp使用多进程方式进行CPE重排序。
1 | def rerank_mp(x2ys, x2cnt, x2xs, width, n_trans, num_workers): |
基于词向量的方法
参考论文:
(1)A Survey Of Cross-lingual Word Embedding Models
https://arxiv.org/abs/1706.04902
http://ir.hit.edu.cn/~xiachongfeng/slides/x-lingual-v1.0.pdf
https://zhuanlan.zhihu.com/p/69366459
(2)Word Translation Without Parallel Data
https://arxiv.org/abs/1710.04087
(3)Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
https://arxiv.org/abs/1812.10464
https://github.com/yannvgn/laserembeddings
(4)Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion
https://arxiv.org/pdf/1804.07745.pdf
https://fasttext.cc/docs/en/aligned-vectors.html
跨语言词向量综述
A Survey Of Cross-lingual Word Embedding Models这篇论文中对跨语言的词向量的相关研究进行了总结,并且发现很多模型其实本质上是一个模型,只是使用了不同的目标函数和数据。为了方便理解,我们先将后续用到的符号进行说明:

我们使用$\operatorname{sen} t_{1}^{s}, \ldots, \operatorname{sen} t_{n}^{s}$表示源语言的句子序列$\mathbf{y}_{1}^{s}, \ldots, \mathbf{y}_{n}^{s}$,$\operatorname{sen} t_{1}^{t}, \ldots, \operatorname{sen} t_{n}^{t}$表示与之对齐的目标端语言的句子序列$\mathbf{y}_{1}^{t}, \ldots, \mathbf{y}_{n}^{t}$。同样的,用$d o c_{1}^{s}, \ldots, d o c_{n}^{s}$表示源语言的文档$\mathbf{z}_{1}^{s}, \ldots, \mathbf{z}_{n}^{s}$。用$d o c_{1}^{t}, \ldots, d o c_{n}^{t}$表示目标语言的文档$\mathbf{z}_{1}^{t}, \ldots, \mathbf{z}_{n}^{t}$。
基本上所有模型的目标函数都可以写成:$J=\mathcal{L}^{1}+\ldots+\mathcal{L}^{\ell}+\Omega$,其中$\mathcal{L}^{\ell}$表示第l个语种的monolingual loss,$\Omega$是一个正则项。
词向量综述
在正式介绍跨语言词向量模型前,我们简单介绍一下词向量的发展史。从刚才介绍的用LSA矩阵分解的方法开始,后续产生了基于Max-margin loss来最大化correct word sequence和incorrect word sequence的hinge loss:$\begin{aligned}
&\mathcal{L}_{\mathrm{MML}}=\sum_{k=C+1}^{|\mathcal{C}|-C} \sum_{w^{\prime} \in V} \max \left(0,1-f\left(\left[\mathbf{x}_{w_{k-C}}, \ldots, \mathbf{x}_{w_{i}}, \ldots, \mathbf{x}_{w_{k+C}}\right]\right)\right.\\
&\left.+f\left(\left[\mathbf{x}_{w_{k-C}}, \ldots, \mathbf{x}_{w^{\prime}}, \ldots, \mathbf{x}_{w_{k+C}}\right]\right)\right)
\end{aligned}$
接着又有了比较出名的Skip-gram with negative sampling方法:$\mathcal{L}_{\mathrm{SGNS}}=-\frac{1}{|\mathcal{C}|-C} \sum_{k=C+1}^{|\mathcal{C}|-C} \sum_{-C \leq j \leq C, j \neq 0} \log P\left(w_{k+j} | w_{k}\right)$,其中P使用softmax计算:$P\left(w_{k+j} | w_{k}\right)=\frac{\exp \left(\tilde{\mathbf{x}}_{w_{k+j}}^{\top} \mathbf{x}_{w_{k}}\right)}{\sum_{i=1}^{|V|} \exp \left(\tilde{\mathbf{x}}_{w_{i}} \top_{\mathbf{x}_{w_{k}}}\right)}$,为了减少计算量使用了negative-sample的方法:$P\left(w_{k+j} | w_{k}\right)=\log \sigma\left(\tilde{\mathbf{x}}_{w_{k+j}}^{\top} \mathbf{x}_{w_{k}}\right)+\sum_{i=1}^{N} \mathbb{E}_{w_{i} \sim P_{n}} \log \sigma\left(-\tilde{\mathbf{x}}_{w_{i}}^{\top} \mathbf{x}_{w_{k}}\right)$。正如在本篇上文中介绍,这种负采样方法,通过数学推导可以发现,本质上和矩阵分解的作用是一样的。
后来又有了Continuous bag-of-words(CBOW)模型:$\mathcal{L}_{\mathrm{CBOW}}=-\frac{1}{|\mathcal{C}|-C} \sum_{k=C+1}^{|\mathcal{C}|-C} \log P\left(w_{k} | w_{k-C}, \ldots, w_{k-1}, w_{k+1}, \ldots, w_{k+C}\right)$,其中$P\left(w_{k} | w_{k-C}, \ldots, w_{k+C}\right)=\frac{\exp \left(\tilde{\mathbf{x}}_{w_{k}}^{\top} \overline{\mathbf{x}}_{w_{k}}\right)}{\sum_{i=1}^{|V|} \exp \left(\tilde{\mathbf{x}}_{w_{i}} \top \overline{\mathbf{x}}_{w_{k}}\right)}$,$\overline{\mathbf{x}}_{w_{k}}$是$w_{k-C}, \dots, w_{k+C}$词向量的平均值。
再后来就有了我们常用的Glove词向量模型:$\mathcal{L}_{\mathrm{GloVe}}=\sum_{i, j=1}^{|V|} f\left(\mathbf{C}_{i j}\right)\left(\mathbf{x}_{w_{i}}^{\top} \tilde{\mathbf{x}}_{w_{j}}+b_{i}+\tilde{b}_{j}-\log \mathbf{C}_{i j}\right)^{2}$,其中$C_{ij}$计算$w_i$和$w_j$在给定窗口大小下共现的次数。如果我们令$b_{i}=\log c\left(w_{i}\right)$、$\tilde{b}_{j}=\log c\left(w_{j}\right)$,则会发现Glove模型实际上也是对一个PMI矩阵(进行$log|C|$ shift后)进行分解。
Typology
训练跨语言词向量的方法,跟使用什么类型的语料有关,如下图,你可以使用平行词典、可比词典、平行语料或者可比语料等等:

下面这张图展示了整个跨语言向量的路线图:
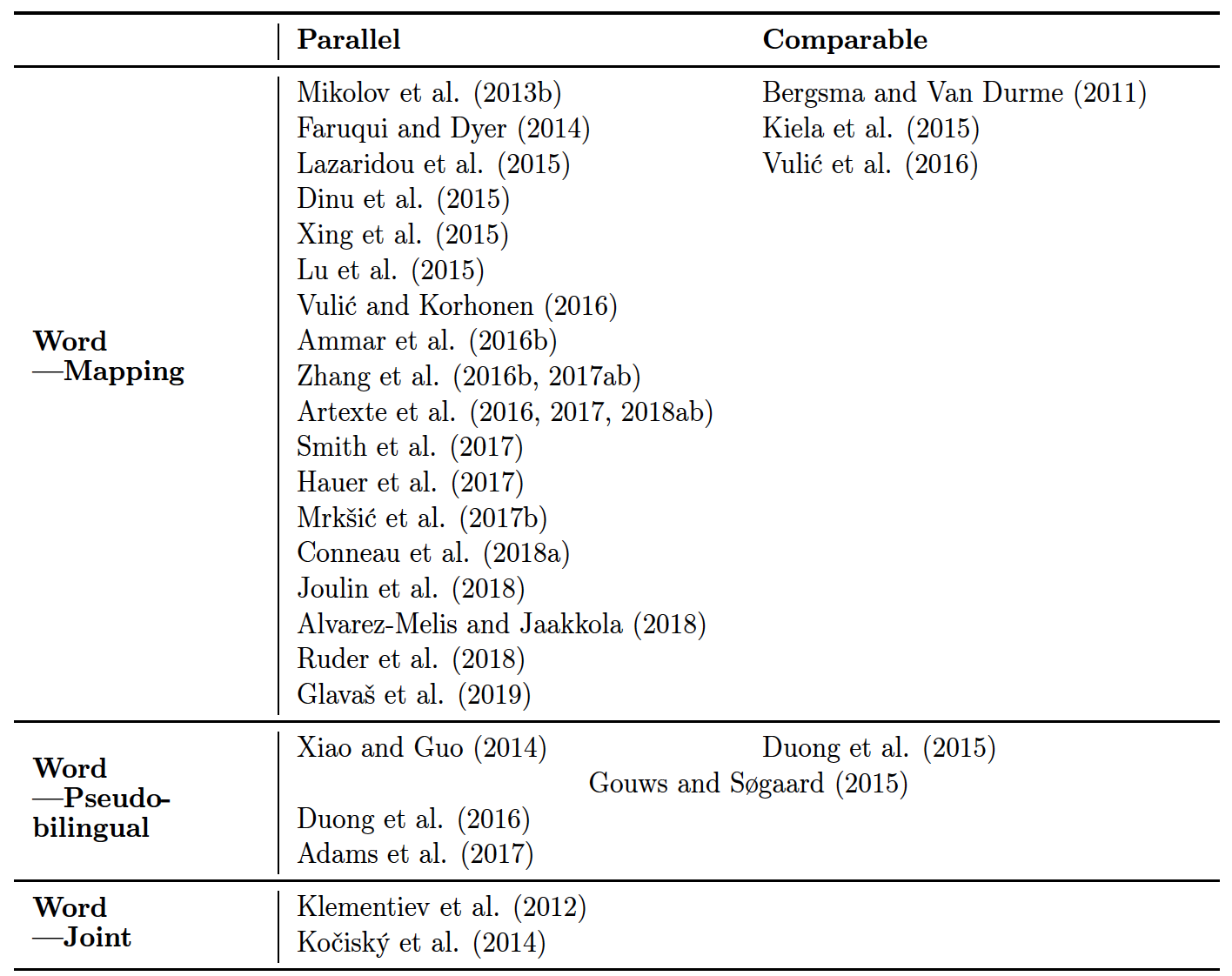

Word-Level Alignment Models
首先我们来看基于词对齐的方法。基于词对齐可以使用两种语料:平行语料、可比语料。基于平行语料的方法大致分3种:
- Mapping-based:通过学习平行语料或者平行词典的映射关系,现训练一个源语言的embedding,再用学习到的映射矩阵映射到目标语言词向量空间中
- Pseudo-multi-lingual corpora-based:用跨语言的伪语料来捕捉不同语言单词间的相互作用,这个伪语料是人工构造的。例如根据翻译,可以定义英语 house 和法语 maison 是等价 的,根据词性标注,可以定义英语 car 和法语 maison 都是名词是等价的。因此这里的对齐方式不一 定是翻译,可以根据具体的任务来定义,然后利用这种对齐关系来构造双语伪语料。首先将源语言 和目标语言数据混合打乱。对于统一语料库中一句话的每一个词语,如果存在于对齐关系中,以一 定概率来替换为另一种语言的词语。通过该方法可以构建得到真实的双语语料库。例如根据翻译关 系,原始句子 build the house 经过构建可以得到 build the maison,就是将 house 替换为了 maison。 利用构建好的全部语料来使用 CBOW 算法学习词向量,由于替换以后的词语有相似的上下文,因 此会得到相似的表示。对于那些没有对齐关系的词语,例如“我吃苹果”和“I eat apple”,吃和 eat 没有对齐关系,但如果我和 I、苹果和 apple 有对齐关系,根据构造出来的语料“I 吃 apple”也可 以完成吃和 eat 的隐式对齐。这种方法对齐词语有相似表示。
- Joint-method:利用平行语料来最小化monolingual losses + cross-lingual regularization term
基于可比语料的方法大致分2种:
- Language grounding models:把图片作为anchor,通过图片特征来获得language similarity的特征
- Comparable feature models:利用POS信息建立两个language的桥梁
基于Mapping的方法有以下4个要素:
- mapping method:负责将monolingual embedding spaces转换到cross-lingual embedding space。Mapping method有以下几种方法:
- Regression methods
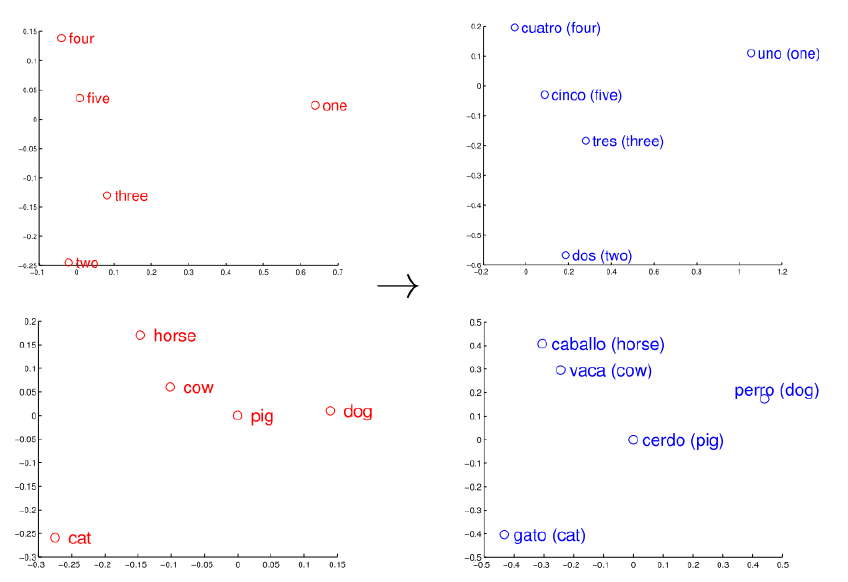
- 学习source到target的转移矩阵,并最大化source embedding和target embedding的相似度:$\Omega_{\mathrm{MSE}}=\sum_{i=1}^{n}\left|\mathbf{W} \mathbf{x}_{i}^{s}-\mathbf{x}_{i}^{t}\right|^{2}$,其中$x^s_i$是source embedding,经过W转换后,希望最小化它和其真正的翻译$x^t_i$的embedding之间的距离。论文认为这个目标函数也可以写成这种形式:$J=\underbrace{\mathcal{L}_{\mathrm{SGNS}}\left(\mathbf{X}^{s}\right)+\mathcal{L}_{\mathrm{SGNS}}\left(\mathbf{X}^{t}\right)}_{1}+\underbrace{\Omega_{\mathrm{MSE}}\left(\underline{\mathbf{X}}^{s}, \underline{\mathbf{X}}^{t}, \mathbf{W}\right)}_{2}$。Regression method的想法来源于一个观察,就是source word之间的相关性,和他们的所对应的target word之间的相关性相似,如下图:
- Regression methods
- Orthogonal methods
- 同Regression method,但要求W是正交的,即$\mathbf{W}^{\top} \mathbf{W}=\mathbf{I}$
- Canonical methods
- 将source和target共同映射到另一个空间,并最大化两个embedding的相似度。我们定义映射后的两个单词的相关性为:$\rho\left(\mathbf{W}^{s \rightarrow} \mathbf{x}_{i}^{s}, \mathbf{W}^{t \rightarrow} \mathbf{x}_{i}^{t}\right)=\frac{\operatorname{cov}\left(\mathbf{W}^{s \rightarrow} \mathbf{x}_{i}^{s}, \mathbf{W}^{t \rightarrow} \mathbf{x}_{i}^{t}\right)}{\sqrt{\operatorname{var}\left(\mathbf{W}^{s \rightarrow \mathbf{x}_{i}^{s}}\right) \operatorname{var}\left(\mathbf{W}^{t \rightarrow \mathbf{x}_{i}^{t}}\right)}}$,则canonical method的目标是最大化所有的相关性:$\Omega_{\mathrm{CCA}}=-\sum_{i=1}^{n} \rho\left(\mathbf{W}^{s \rightarrow} \mathbf{x}_{i}^{s}, \mathbf{W}^{t \rightarrow} \mathbf{x}_{i}^{t}\right)$。论文认为这个目标函数等价于:$J=\underbrace{\mathcal{L}_{\mathrm{LSA}}\left(\mathbf{X}^{s}\right)+\mathcal{L}_{\mathrm{LSA}}\left(\mathbf{X}^{t}\right)}_{1}+\underbrace{\Omega_{\mathrm{CCA}}\left(\underline{\mathbf{X}}^{s}, \underline{\mathbf{X}}^{t}, \mathbf{W}^{s \rightarrow}, \mathbf{W}^{t \rightarrow}\right)}_{2}$
- Margin methods
- 该方法将Loss函数改成了margin-based rank loss来减轻hubness的问题:$\Omega_{\mathrm{MML}}=\sum_{i=1}^{n} \sum_{j \neq i}^{k} \max \left\{0, \gamma-\cos \left(\mathbf{W} \mathbf{x}_{i}^{s}, \mathbf{x}_{i}^{t}\right)+\cos \left(\mathbf{W} \mathbf{x}_{i}^{s}, \mathbf{x}_{j}^{t}\right)\right\}$,并认为此时目标函数就是:$J=\underbrace{\mathcal{L}_{\mathrm{CBOW}}\left(\mathbf{X}^{s}\right)+\mathcal{L}_{\mathrm{CBOW}}\left(\mathbf{X}^{t}\right)}_{1}+\underbrace{\Omega_{\mathrm{MML}-\mathrm{I}}\left(\underline{\mathbf{X}}^{s}, \mathbf{X}^{t}, \mathbf{W}\right)}_{2}$
- seed lexicon:用于学习embedding的种子字典
- refinement:用于修正学习到的mapping
- retrieval:用于搜索最近邻
Sentence-Level Alignment Methods
基于平行语料的方法也可以分为4种:
- Word-alignment based matrix factorization approaches
- 基于Word-alignment的方法可以先用FastAlign找到词对齐关系。如果一个source word在target空间中只有一个翻译,那么这个target翻译的embedding应该是确定的一个,但如果它在target空间中有多个翻译,那么应该认为target的embedding应该是这些翻译的一个加权平均。这就是word-alignment方法的基本思路,其目标函数为:$\Omega_{s \rightarrow t}=\left|\mathbf{X}^{t}-\mathbf{A}^{s \rightarrow t} \mathbf{X}^{s}\right|^{2}$,也可以写成:$J=\underbrace{\mathcal{L}_{\mathrm{MML}}\left(\mathbf{X}^{t}\right)}_{1}+\underbrace{\Omega_{s \rightarrow t}\left(\underline{\mathbf{X}}^{t}, \underline{\mathbf{A}}^{s \rightarrow t}, \mathbf{X}^{s}\right)}_{2}$。之所以叫factorization approach是因为有的方法将$A^{s->t}$看成是共现矩阵并用Glove的目标函数进行分解
- Compositional sentence models
- 这种方法将平行句子表示的距离最小化,即$E_{\text {dist}}\left(\operatorname{sen} t^{s}, \operatorname{sen} t^{t}\right)=\left|\mathbf{y}^{s}-\mathbf{y}^{t}\right|^{2}$,其中句子的表示使用单词表示的和,使用hinge loss作为目标函数:$\mathcal{L}=\sum_{\left(s e n t^{s}, s e n t^{t}\right) \in \mathcal{C}} \sum_{i=1}^{k} \max \left(0,1+E_{\text {dist}}\left(\operatorname{sent}^{s}, \operatorname{sent}^{t}\right)-E_{\text {dist}}\left(\operatorname{sent}^{s}, s_{i}^{t}\right)\right)$,或者$J=\mathcal{L}\left(\mathbf{X}^{s}, \mathbf{X}^{t}\right)+\Omega\left(\mathbf{X}^{s}\right)+\Omega\left(\mathbf{X}^{t}\right)$
- Bilingual autoencoder models
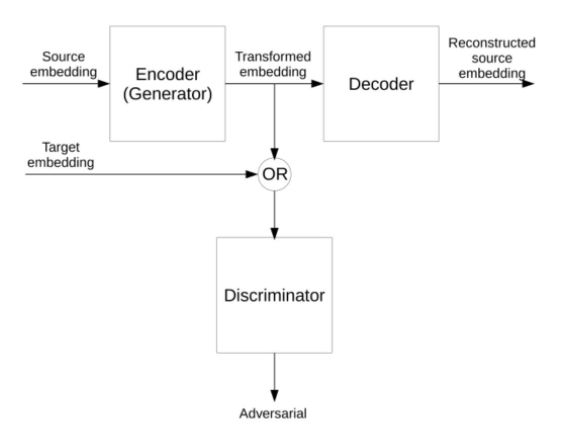
- 从这里开始就开始无监督的工作了,Barone开始使用对抗自动编码器将源语言词嵌入转换到目标语言中,然后训练自动编码器以重建源嵌入,同时训练鉴别器以将投射的源嵌入与实际目标嵌入区分开,如下图:
- Bilingual skip-gram models
论文中还讲解了Document-Level Alignment Models,训练以及评测。内容太多,也没看,在此不继续写这篇综述了。感兴趣的读者可以再去看看论文。
词向量训练还有BERT等方法,[Devlin et al., 2018] 提出了 Multilingual BERT,与单语 BERT 结构一样,使用共享的 Wordpiece 表示,使用了 104 中语言进行训练。训练时,无输入语言标记,也没有强制对齐的语料有相 同的表示。[Pires et al., 2019] 分析了 Multilingual BERT 的多语言表征能力,得出了几点结论: Multilingual BERT 的多语言表征能力不仅仅依赖于共享的词表,对于没有重叠(overlap)词汇语 言的 zero-shot 任务,也可以完成的很好;语言越相似,效果越好;对于语言顺序(主谓宾或者形 容词名词)不同的语言,效果不是很好;Multilingual BERT 的表示同时包含了多种语言共有的表 示,同时也包含了语言特定的表示,这一结论,[Wu and Dredze, 2019] 在语言分类任务中也指出, Multilingual BERT 由于需要完成语言模型任务,所以需要保持一定的语言特定的表示来在词表中 选择特定语言词语。
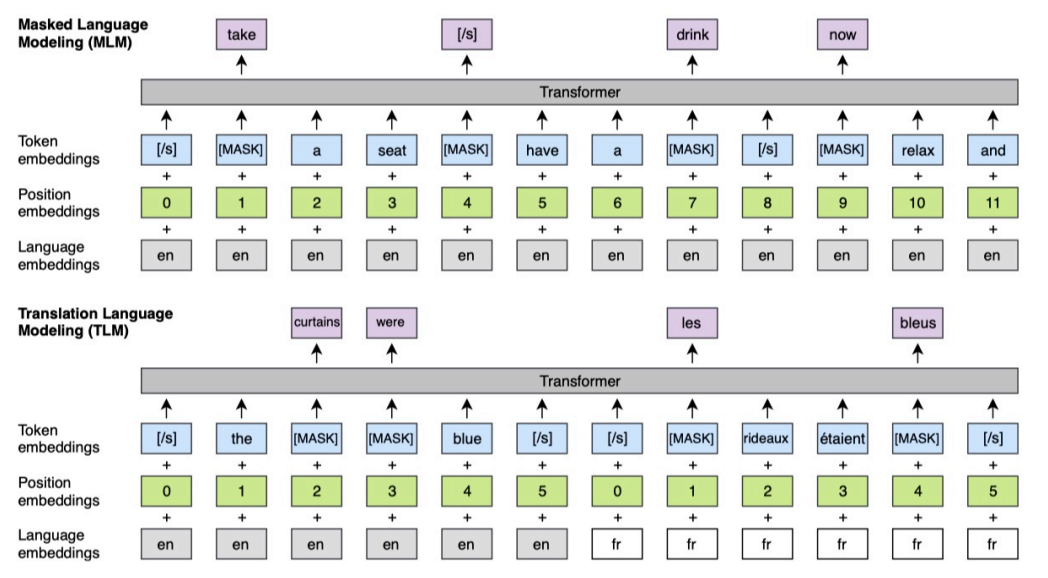
[Lample and Conneau, 2019] 提出了基于多种语言预训练的模型 XLMs,首先从单语语料库中 采样一些句子,对于资源稀少的语言可以增加数量,对于资源丰富的语言可以减少数量,将所有语 言使用统一 BPE 进行表示。使用三种语言模型目标来完成学习。前两个是基于单语语料库的,最 后一个是基于双语对齐数据的。第一种是 Causal Language Modeling (CLM),根据之前的词语预 测下一个词语。第二个是 Masked Language Modeling (MLM),和 BERT 类似,但是使用一个词 语流,而非句子对。第三种是 Translation Language Modeling (TLM),可以随机 mask 掉其中一些 两种语言中的一些词语,然后进行预测。其模型如下:
一些好用的工具
这里推荐两个,一个是fast-text的align-vector,可以在https://fasttext.cc/docs/en/aligned-vectors.html下载,如果想训练可以参考https://github.com/facebookresearch/fastText/tree/master/alignment。
另一个是laser,其主项目在https://github.com/facebookresearch/LASER,如果想直接使用multi-lingual的sentence embedding,可以参考https://github.com/yannvgn/laserembeddings。顺便说下,这两个都是facebook的工作。