CRF是NLP中很常用且经典的模型,今天就复习一下CRF模型。
参考:
https://arxiv.org/abs/1011.4088
http://cseweb.ucsd.edu/~elkan/250Bwinter2012/loglinearCRFs.pdf
前言
生成模型 VS 判别模型
下面这张图展示了生成模型和判别模型的联系和区别:这两种模型都是用极大似然估计来估计概率,只是两个估计的概率公式不同,生成模型是$p(x, y)$,判别模型是$p(y|x)$。为什么生成模型能生成数据呢,因为$p(x, y) = p(y) * p(x|y)$,我们可以学习到$p(x|y)$,那么当我们采样y时,就可以根据它生成x了。
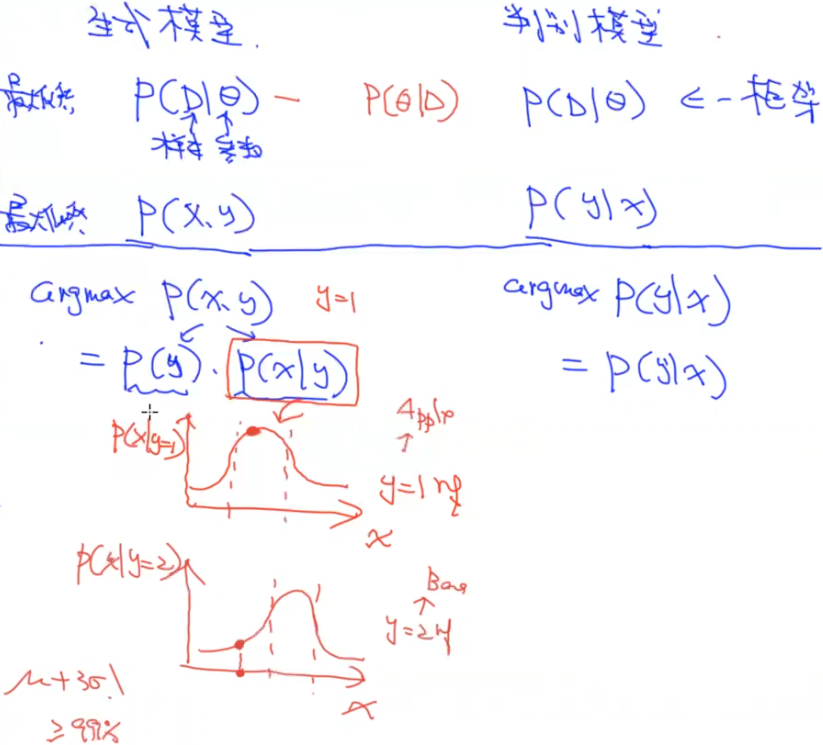
生成模型可以用于生成,也可以用于判别。但判别模型只能用于判别。生成模型需要学习到更多有关数据的细节。比如有很多猫和狗的图片,对于生成模型,它就会学到很多猫和狗的长什么样的细节(因为学不到的话它也生成不出来);但对于判别模型,主要学习到猫和狗的区别,如下图:
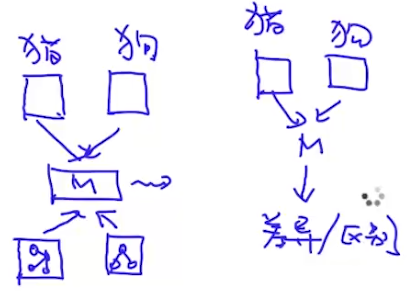
生成模型的目标函数是P(x, y),而判别函数是P(y|x)。转化$P(x,y)=P(y)P(x|y)$,也就是生成模型学习到的一个是$P(x|y)$,比如对于y=猫来说,能学习到一个x的分布(即猫的特征分布,有时这个分布用高斯分布去模拟),如下图:
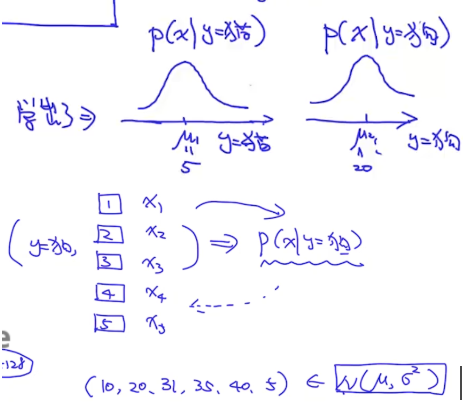
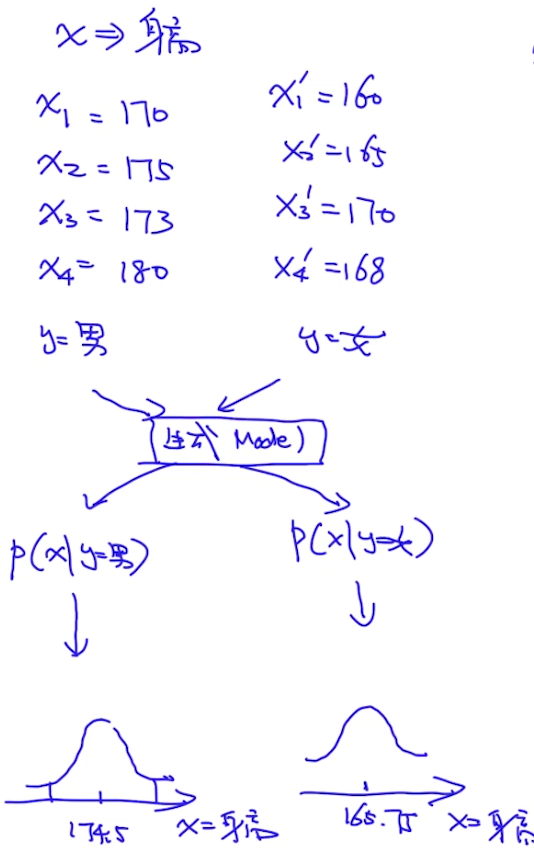
那怎么生成呢?事实上我们可以从$P(x|y=猫)$这个分布中去采样一个x(比如对于图片来说,x就是像素矩阵),而这个x就是一个猫的图片了。下面再以预测男、女身高为例,做一个生成模型,过程如下图(当需要生成时,直接从正太分布x~$N(\mu, \sigma^2$)中采样即可):
那么在判别问题上,哪个模型效果更好呢?从生成视角看,生成式建模的是$P(x,y)=P(y)P(x|y)$,从判别视角看,生成式建模的是$P(x,y)=P(x)P(y|x)$。而判别式建模的就是$P(y|x)$。也就是两类模型都去做了判别$P(y|x)$,而生成模型同时学习了$P(x)$(可以理解成一个prior)。从直观上感觉,只做一件事情的判别模型会更好。因为生成模型要同时兼顾$P(x)$和$P(y|x)$,它要找到这两者之间的一个平衡点。因此,我们可以得出以下结论:
- 当数据量大时,使用判别模型会优于生成模型
- 当数据量小时,生成模型有可能比判别模型要好(因为生成模型有prior,即p(x),有时为了防止过拟合,会在模型中加入正则项,其实这个正则项就是一个prior)
【注】:上面提到的p(x, y)、p(x|y)其实是所有概率的乘积,即
Directed Model VS Undirected Model
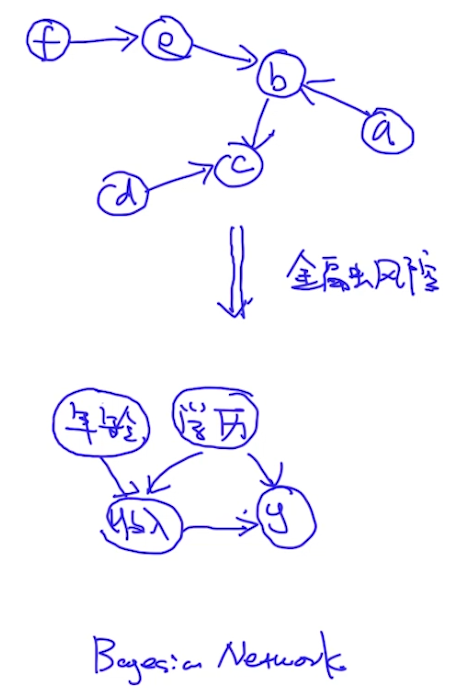
有明确依赖关系的叫有向图。比如做金融风控,如下图:
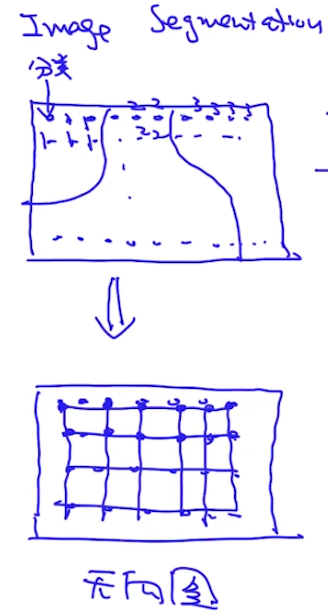
没有依赖关系的叫无向图。比如在做Image Segmentation时,需要对每个点进行分类。如果把每个点看成时独立的话,缺少了像素点之间的联系。因此可以把它看成一个graphic model。因为点之间很难有方向的关系,因此使用无向图:
Joint Probability
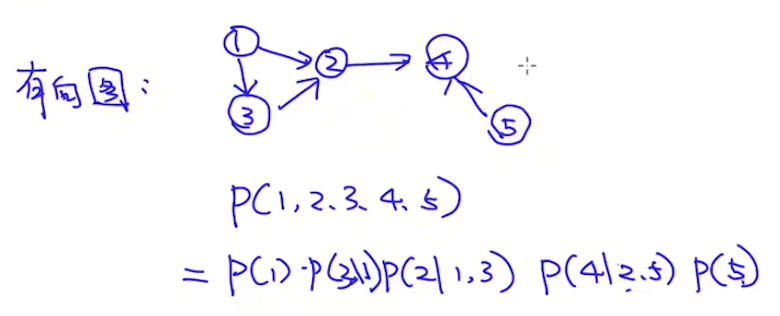
使用联合概率来建模图模型(后续可以用这个联合概率进行分类)。有向图的联合概率很好写:
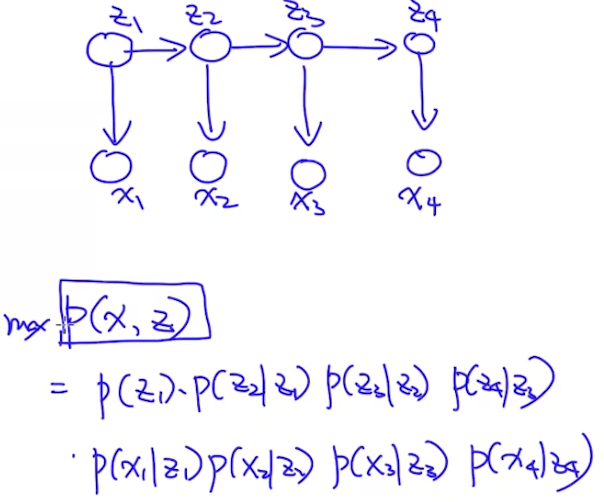
在生成模型HMM中,其概率公式如下图:
无向图有两种方法建模:
- Maximal Clique方法:先分成团,每个团用score function计算一个契合度。而这个契合度和团里的元素的联合概率是正相关的,因此这个score function也可以用联合概率表示,如下图:
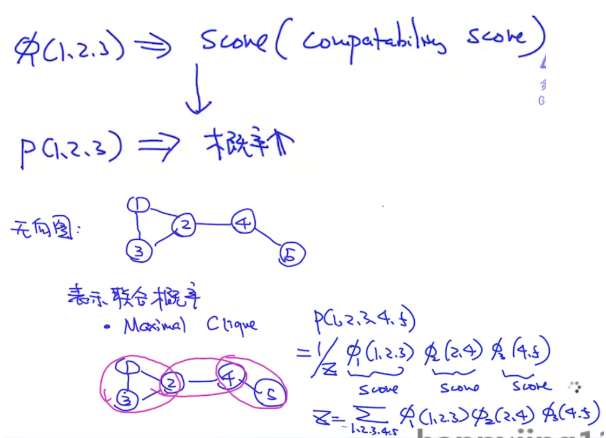
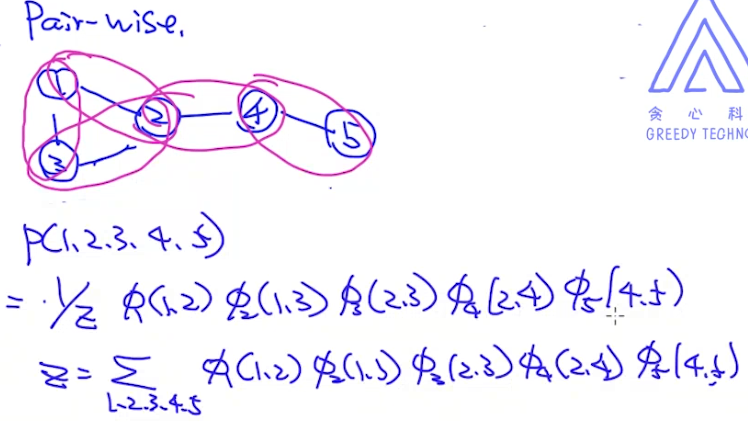
- Pair-wise
【注】:
- 因为score function得出的是一个相对值,不同feature、不同算法得出的结果不一样。但最后我们是想得到P(1,2,3,4,5)这个联合概率的绝对值的(后续做判别时会用到),因此我们除以了一个归一化项z。这个z要考虑所有可能的情况,在实际情况中我们可以使用维特比来简化计算量。
- z是一个global normalization,使用这种全局的归一化有一个好处,就是图中的结点是有一个偏好的,但是z是一个全局的量,可以修正结点的偏好,使得模型考虑得更加全面。
- 在有向图中使用的是local normalization,比如P(4|2,5)只需要关注P(2,5),因此有向图是从局部角度考虑的
- z的计算量比较大,如果变量是离散型的,则可以使用维特比算法;如果变量是连续型的,则只能使用一些近似算法(partition funciton,比如MCMC)
接下来有一个问题,这个score function究竟是怎么计算出来的呢?
首先,我们假设score function计算的是变量之间的compatability。所以,变量之间关系越紧密,则score function结果越大。例如,假设a、b、c是三位学生,他们在一起做项目。则score function可以表示三位学生合作的结果。他们关系越好,合作越紧密,则得分越高。紧接着,我们要考虑这三位学生的一些特征。我们要选择一些特征,能刻画出三位学生是否能合作好。比如三个学生是否来自同一个班级(f1),以及他们之前是否合作过(f2),以及他们之间的能力是否互补(f3)等等。我们可以把这些特征做一个线性组合来得到score(linear model)。当然也可以使用非线性的方式构造score function,这个时候就是log-linear crf。下图概括了这个过程:

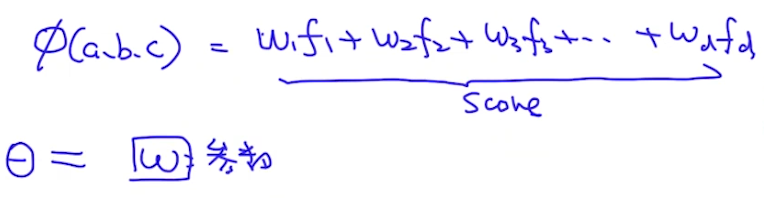
特征工程一般分两种,一种是人工特征,另一种是使用深度学习特征(比如BiLSTM-CRF,卷积核等)。
RoadMap
我们通过对特征函数进行不同假设,可以得到不同模型:
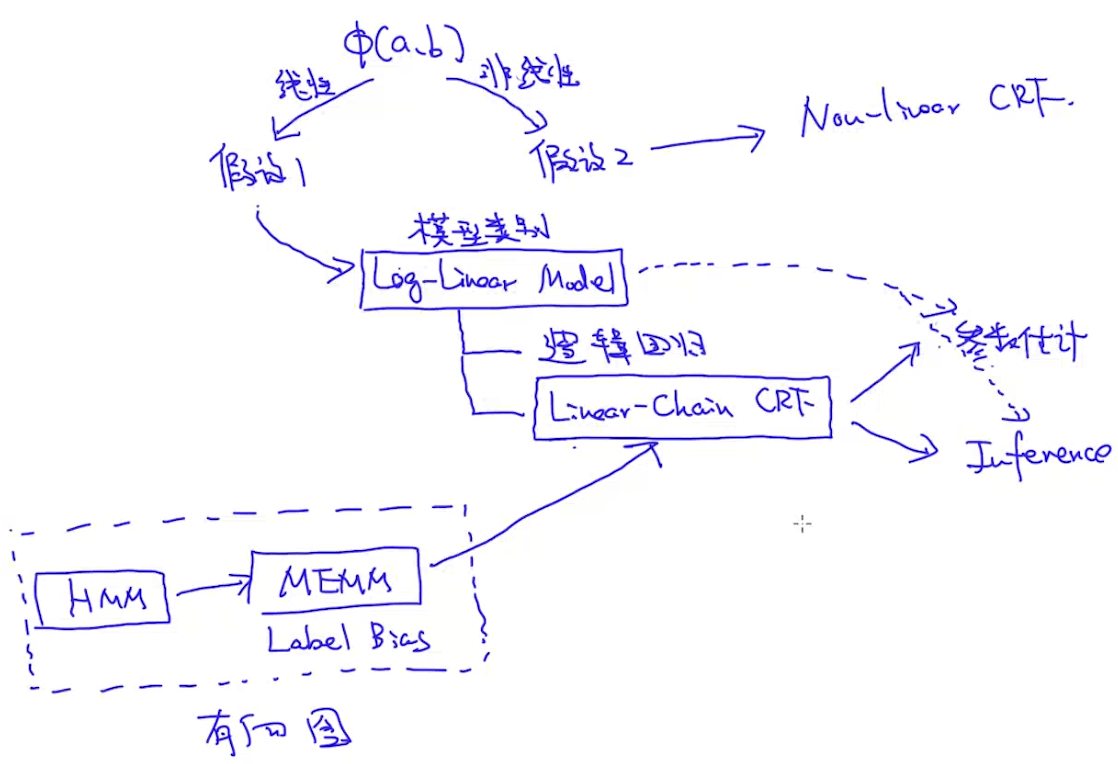
由上图可以看到,假设特征函数是线性函数时,可以产生Log-Linear Model(顾名思义,就是对score funciton先取linear,再取log)。Log-Linear Model的具体模型常见的有逻辑回归和Linear-Chain CRF。那么从另一个角度,有向图模型HMM对于NLP问题有一些缺陷,我们把它从生成模型改造成一个判别模型MEMM,但MEMM有Label Bias的问题,因此我们又把MEMM改成一个无向图模型,就得到了Linear Chain CRF。对于Linear Chain CRF,我们关心的是它的参数估计和Inference算法。因为它也属于Log-Linear Model,所以我们要先学习的是Log-Linear Model的参数估计和Inference。
当然,如果我们假设特征函数是非线性的,会得到Non-linear CRF。
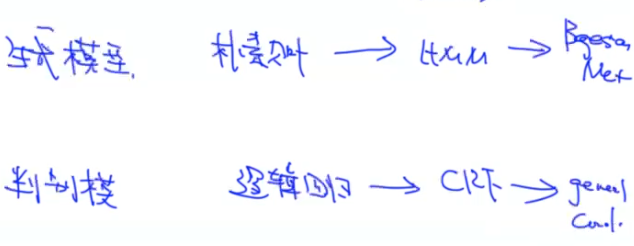
上面这张图是更简明一些的roadmap。对于生成模型,最简单的是朴素贝叶斯,当数据是一条链时,就是HMM,当数据是一个图的时候,就是贝叶斯网络。对于判别模型,最简单的是逻辑回归,当是一条链是就是CRF,当是一个图时就是更general的CRF。
Log-Linear Model
首先我们来看这样一个无向图模型和它的联合概率(用all cliques方法定义联合概率):
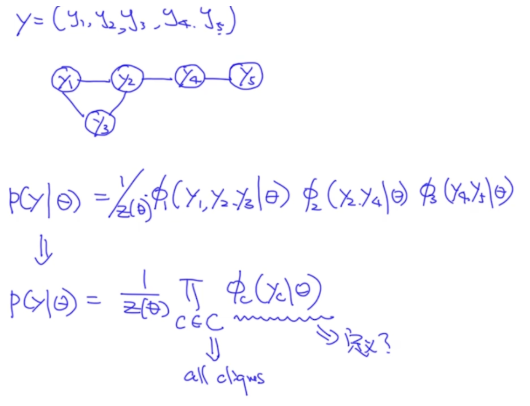
那么接下来的问题就是,如何去定义这个score function呢?我们用一个指数函数计算score:
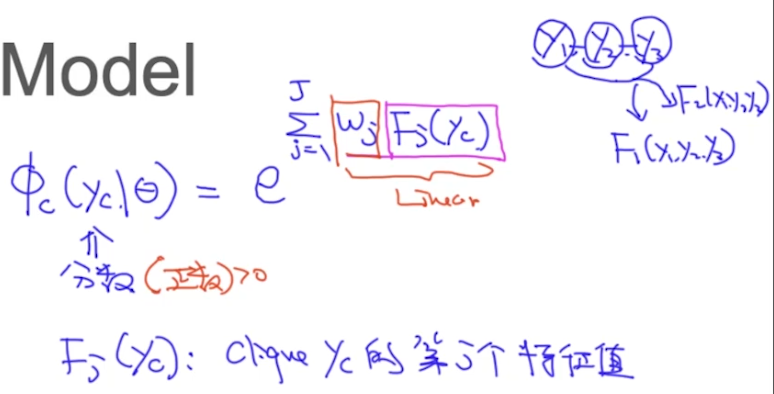
上图式子计算了一个clique的分数,其中$F_j(y_c)$是特征函数。比如$y_1$-$y_2$-$y_3$这个无向图中,我们有2个特征,分别就是$F_1(y_1, y_2, y_3)$、$F_2(y_1, y_2, y_3)$。也就是说,每一个clique里可以抽取出J个特征(每个特征都是一个数)。$w_j*F_j(y_c)$就是一个线性函数,整个模型的参数$\theta={w}$。
那么F特征是什么呢?F主要评估了变量之间的契合度。那为什么这个模型叫Log-Linear呢?看下图就知道了:
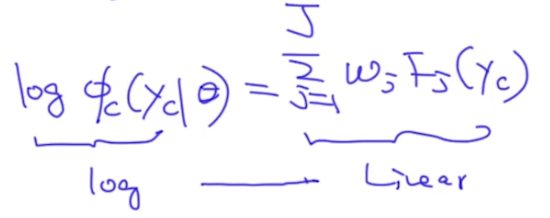
下面用文本的一个例子来说明计算这个联合概率的过程:

Multinomial Logistic Regression
我们可以将逻辑回归看成是x、y的一个无向图:
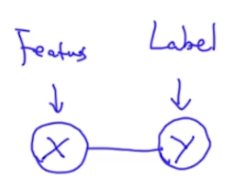
那么逻辑回归的条件概率是什么呢?(这里我们把每个标签作为一个clique)
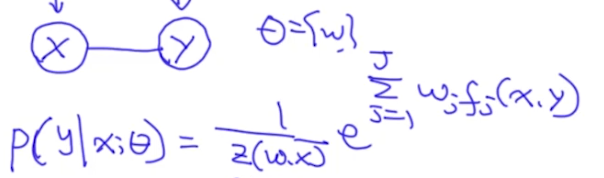
其中特征函数f_j定义如下,可以看出来我们并没有做特征工程,而是把输入x_j直接看成是特征:
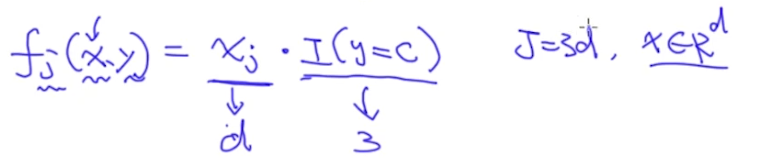
那么一共有多少特征呢?如果标签y有3个(即y={1,2,3}),x的维度为d,则特征总个数为3d,即J=3d。比如,我们分别令y = 1, 2, 3,则$f_j$的具体值如下:
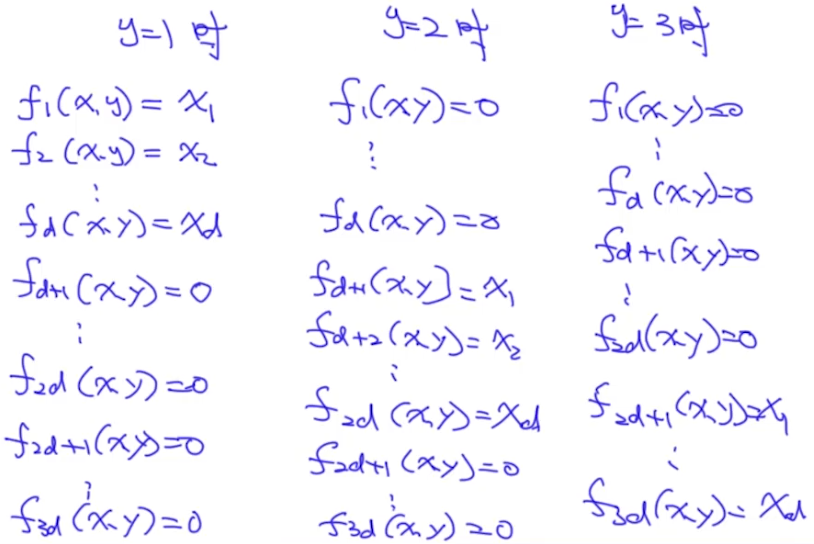
接着,我们把$f_j$的值带入到$P(y|x;\theta)$中:
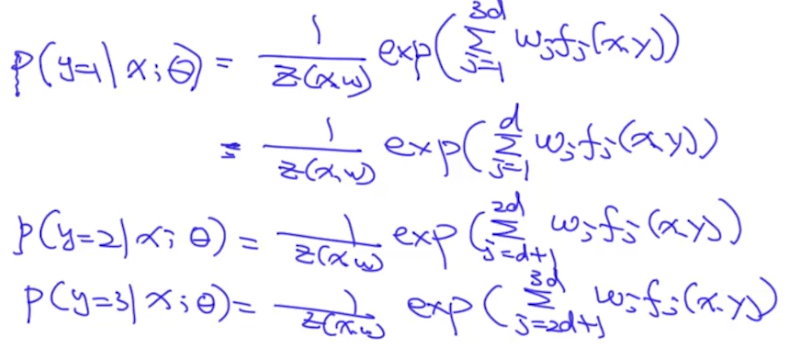
可以看出来,参数w的维度是3d。我们把上面式子在形式上进行一些简化:
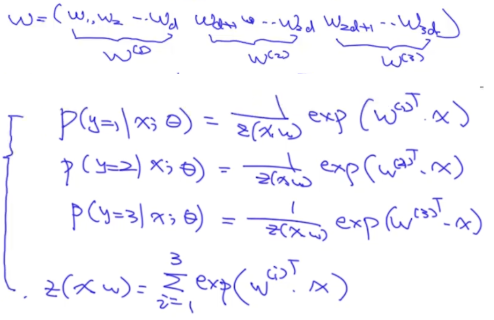
可以看出来这就是一个多元逻辑回归模型(可以用在多分类问题上)。
HMM存在的一些问题
MEMM
假设我们用HMM做词性标注,构建如下模型,会发现有什么问题?
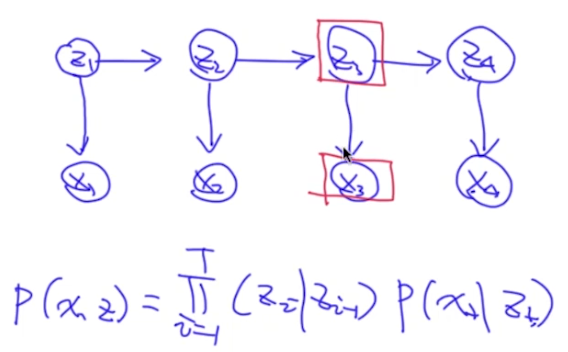
很显然,对于词性标注而言,词性$z_1$不仅仅只依赖于当前词$x_3$,还可能跟其他词有关。那么怎么改进这个模型呢?为了让$z_1$跟所有词相关,我们把它改造成下图:
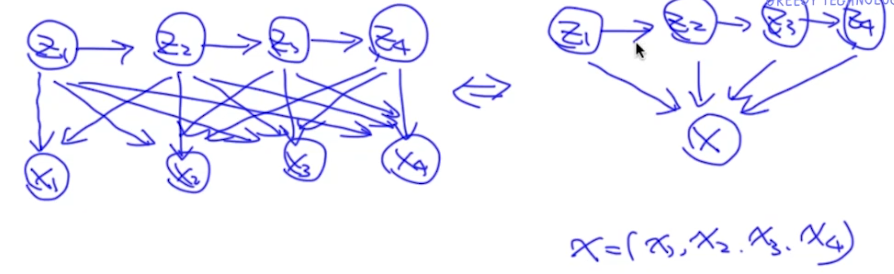
但上图这个模型又有什么问题呢?我们先写一下上图的联合概率:

可以发现上式中第二项,也就是发射概率,是很难表示的。如果说联合概率很难表示,能不能把它改造成一个判别模型呢,用条件概率去表示呢?下图就是改造后的判别模型:
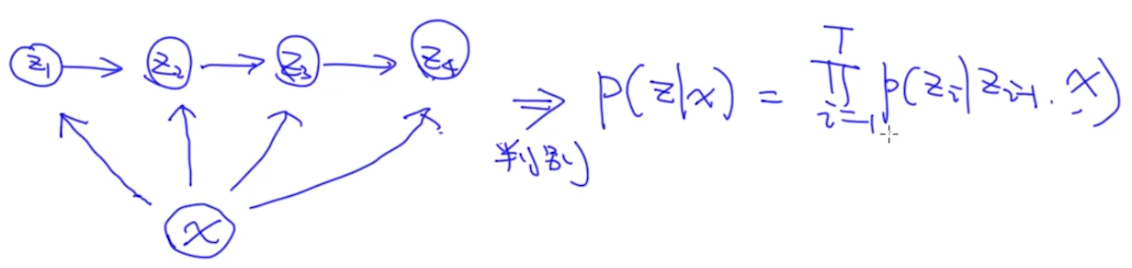
我们可以看出来上图中$P(z_i|z_{i-1}, x)$是很好表示的(比如用一个线性函数+softmax),那么这个模型就是MEMM模型。下面这张图是MEMM的另一种表示:
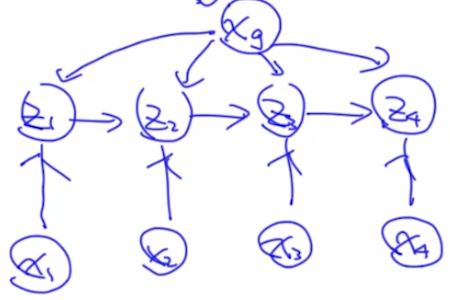
但是MEMM有什么问题呢?
Label Bias Problem
首先,我们来看一看什么叫Label Bias。我们先来看下图,哪一条路径的概率最大呢?
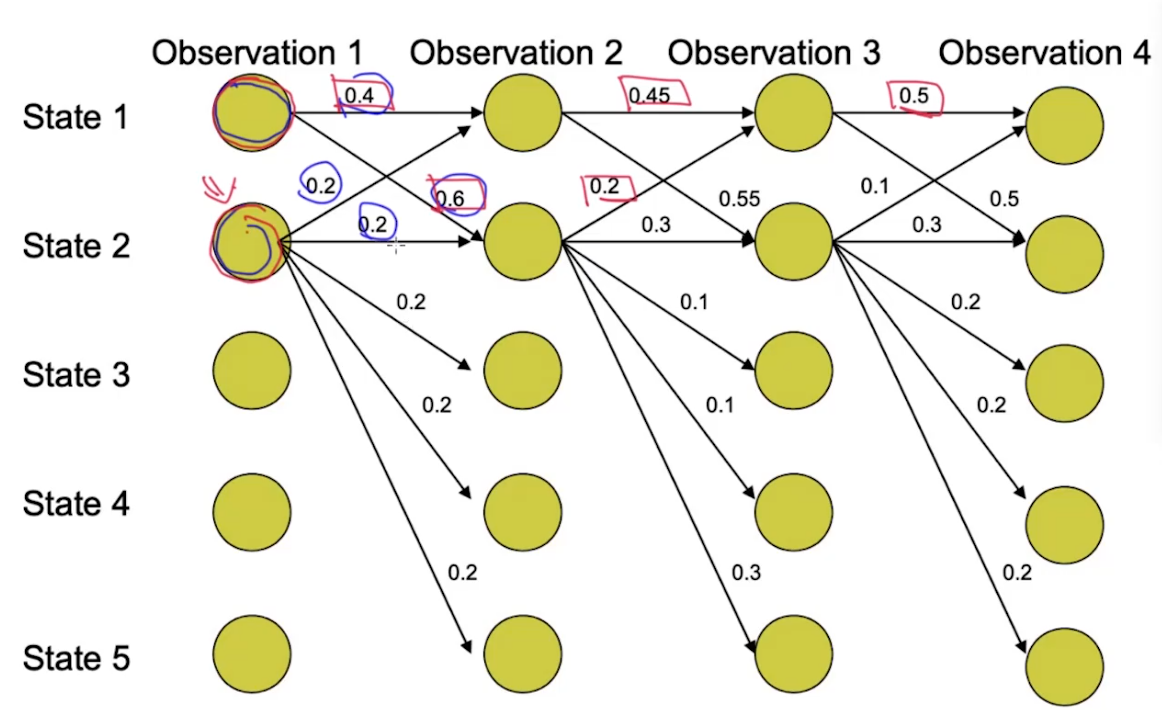
很明显,分支比较多的状态的概率概率较小(相对而言不对它们不是很公平),分支较少的路径概率更大。举个例子,做词性分析时,动词的后面可能的词性较少,名词后面的词性就比较多。Label bias的根本原因是local normalization。那么怎么解决这个问题呢?
我们可以把概率换成是score来表示,有了分数,我们就可以用global normalization了。这也就是无向图和有向图的主要区别,如下图:
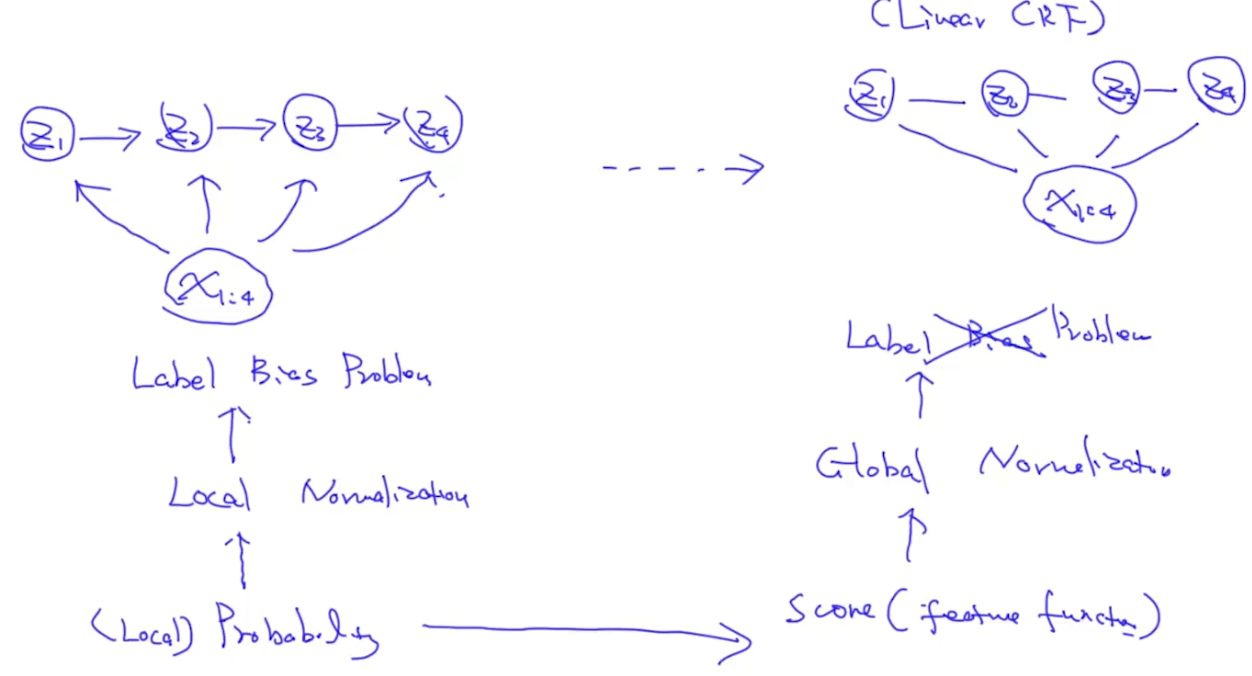
我们可以将(z1, z2)、(z2, z3)、(z3, z4)看成是clique,计算(z1, z2, x)等的feature function (f1, f2, f3, …f10),再进行加权,就有了score。
从Log-linear Model到Log-linear CRF
我们直接从Log-linear的公式进行推导,其实就是把特征函数$f_j(x,y)$表示出来。在无向图中我们把这个特征写成是$F_j(x,y)$(这里的x、y可以看成是一个时间的序列,而不是一个单独的变量)。由于y是一个状态集合,因而(x,y)的特征函数由(y1, y2, x)、(y2, y3, x)、(y3, y4, x)…组成,因此$F_j(x,y)=sum(f_j(y_i, y_{i-1}, x))$。如下图:
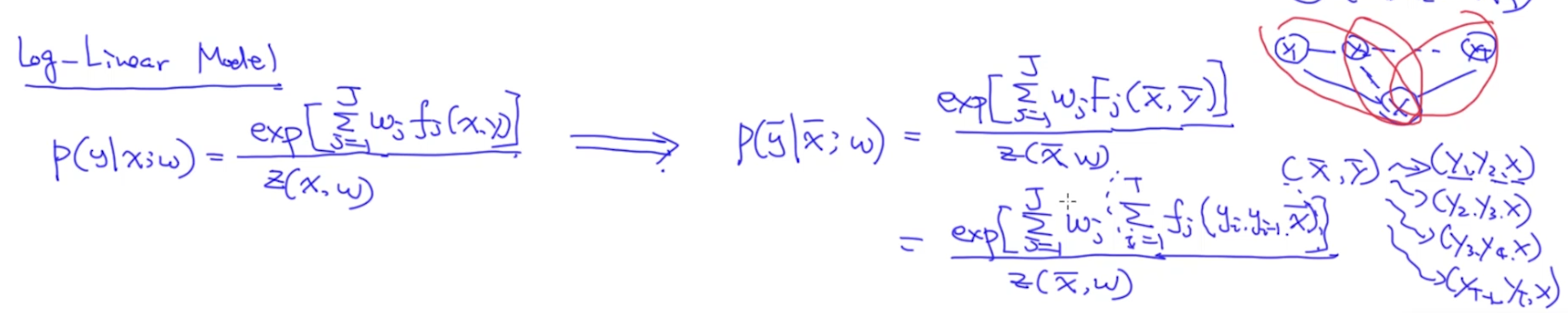
$f_j$可以通过人工,或者神经网络的方式得到,接下来就是求解$w_j$。我们的目标是最大化似然函数: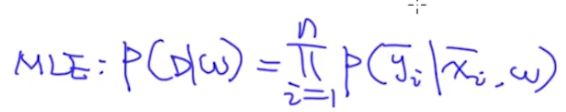 ,因此选择好一个优化方法,就可以求解$w_j$了(比如将loss作为分子对w求偏导)。
,因此选择好一个优化方法,就可以求解$w_j$了(比如将loss作为分子对w求偏导)。
【注】:
- 上式中T是团的个数,在实践序列中,就是timestep-1
- 上式中exp有两个sum,其中第一个sum是对每个clique的结果求和(因为我们要把所有clique的结果乘起来),第二个sum是对每个clique内部所有特征的加和。?好像写反了
- $f_j(y_i, y_{i-1}, x)$中的$f_j$在神经网络中常使用softmax
- $f_j(y_i, y_{i-1}, x)$中的的x可以理解为x1, x2,…,即特征是根据$y_i, y_{i-1}$和所有的x计算出来的,即$f_j(y_i, y_{i-1}, x_1, x_2, …)$
Log-linear CRF
我们的目标是求解:
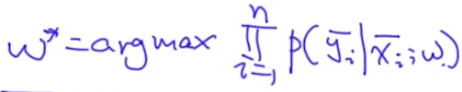
看上去跟逻辑回归差不多,只不过这里的x、y是时间序列。
Inference Probelm
首先我们来看一下,在x、w已知的情况下,我们怎么求解使得P(y|x;w)最大的y。这看上去和逻辑回归没有区别哈,逻辑回归里y={0,1},这里的y是一个序列。
我们先把式子按照定义展开:

看到上面的形式,我们应首先想到维特比算法,一想到维特比算法,就要想到路径,路径的sum值是最大的,如下图(n是时间长度,m是状态个数):

我们定义的子问题是:$u(k, v)$表示从$t=1$到$t=k$,且t时刻的状态为v的最好的路径的分数。我们最终想求的是$max(u(n, 1)$、$u(n, 2)$… $u(n, m))$为最终答案,如下图:
那么我们怎么把$u(k, v)$表示成一个子问题呢?从t=1到t=k一定会经过$u(k-1, 1)$或$u(k-1, 2)$…或$u(k-1, m)$,如下图:
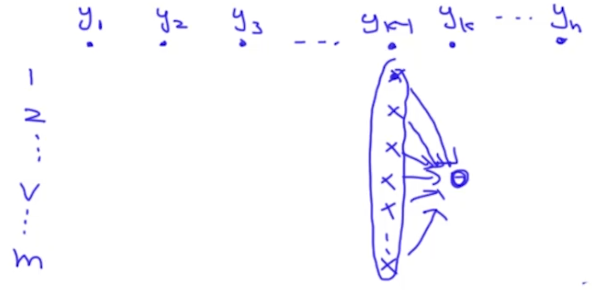
我们用式子表达出来是:
看上去,我们把这个二维的矩阵里的score值逐步填充进去就可以了。当想求解最佳状态的路径时,只需要设置好pointer,反向就能从矩阵中找到最佳路径了。整个算法的复杂度是O(mn)O(m)。
【注】:如果score函数是$g_i(y_{i-2}, y_{i-1}, y_{i})$,那么算法复杂度就可能变为$O(m^2n)O(m)$
Parameter Estimation
Log-Linear的w求解
接下来我们来看,在x、y已知的情况下,我们怎么求解w?求导数就好了。我们先来看一下Log-Linear的w是怎么求解的:

上式中最后一项可以看成是$F_j(x, y’)$的期望:

可以看到第一项$F_j(x, y)$是x、y的特征工程,后一项是关于y’的期望。
Log-Linear CRF的w求解
- 求解partition function z
- Forward算法:在CRF中,partition function z(x, w)中的x变成了一个序列,我们来看一下这个z怎么计算。我们依然可以使用动态规划算法求解$sum(g_i(y_{i-1}, y_i))$。具体如下图所示:

- Forward算法:在CRF中,partition function z(x, w)中的x变成了一个序列,我们来看一下这个z怎么计算。我们依然可以使用动态规划算法求解$sum(g_i(y_{i-1}, y_i))$。具体如下图所示:
上图中$\alpha(k+1, v)$表示$y_{k+1}=v$的情况下,所有状态的可能性。为了求解$\alpha(k+1, v)$,我们把$y_k$作为一个中介,而$y_k$有1~u种可能。举个栗子,假如有4个状态,3个输出,那么我们最后想求$\alpha(4, 1)+\alpha(4,2)+\alpha(4,3)$的和作为z(x, w),且$\alpha(4,1)=\alpha(3,1) + \alpha(3,2) + \alpha(3,3)$,如下图:
Backward算法:跟Forward相似,只不过是$y_k=u$时考虑${y_k{k+1}, y_n}$的所有可能性,这时候$y_{k+1}$成为了中介。


求解$P(y_k=u|x;w)$
- $z(x, w)$是考虑所有的可能性,因此可以认为$z(x, w)=p(y_k=1|x;w) + p(y_k=2|x, w) + … + p(y_k=m|x;w)$
- 根据前向算法和后向算法,可以算出$z(x, w)$
- $p(y_k=u|x;w)$表示$y_k=u$的情况下,前向和后向的所有可能情况,如下图:

为了求出w,我们需要对$p(y|x;w)$求导,
