在NLP中我们经常使用注意力机制处理复杂的问题,那么注意力机制是怎么产生的,都有哪些变种,是如何应用在模型中的呢?本篇我们来对NLP中的注意力机制进行一些总结。
问题背景
神经网络有很强的能力。但是对于复杂任务,需要大量的输入信息和复杂的计算流程。计算机的计算能力是神经网络的一个瓶颈。为了减少计算复杂度,常见的方法有局部连接、权值共享、汇聚操作,但仍然需要:尽量少增加模型复杂度(参数),来提高模型的表达能力。
简单文本分类可以使用单向量表达文本只需要一些关键信息即可,所以一个向量足以表达一篇文章,可以用来分类。对阅读理解来说,文章比较长时,一个RNN很难反应出文章的所有语义信息。对于阅读理解任务来说,编码时并不知道会遇到什么问题。这些问题可能会涉及到文章的所有信息点,如果丢失任意一个信息就可能导致无法正确回答问题。
神经网络中可以存储的信息称为网络容`。 存储的多,参数也就越多,网络也就越复杂。 LSTM就是一个存储和计算单元。输入的信息太多(信息过载问题),但不能同时处理这些信息。只能选择重要的信息进行计算,同时用额外空间进行信息存储。这里有两种方法:
- 信息选择:聚焦式自上而下地选择重要信息,过滤掉无关的信息,也就是注意力机制。
- 外部记忆: 优化神经网络的记忆结构,使用额外的外部记忆,来提高网络的存储信息的容量,即记忆力机制。
比如,一篇文章,一个问题。答案只与几个句子相关。所以只需把相关的片段挑选出来交给后续的神经网络来处理,而不需要把所有的文章内容都给到神经网络。
注意力机制Attention Mechanism是解决信息过载的一种资源分配方案,把计算资源分配给更重要的任务。就像人脑可以有意或无意地从大量的输入信息中,选择小部分有用信息来重点处理,并忽略其它信息。一般可以分为聚焦式注意力和显著性注意力两种:
- 聚焦式注意力:自上而下有意识的注意力。有预定目的、依赖任务、主动有意识的聚焦于某一对象的注意力。
- 显著性注意力:自下而上无意识的注意力。由外界刺激驱动的注意力,无需主动干预,也和任务无关。如Max Pooling和Gating。
普通注意力机制
加性注意力
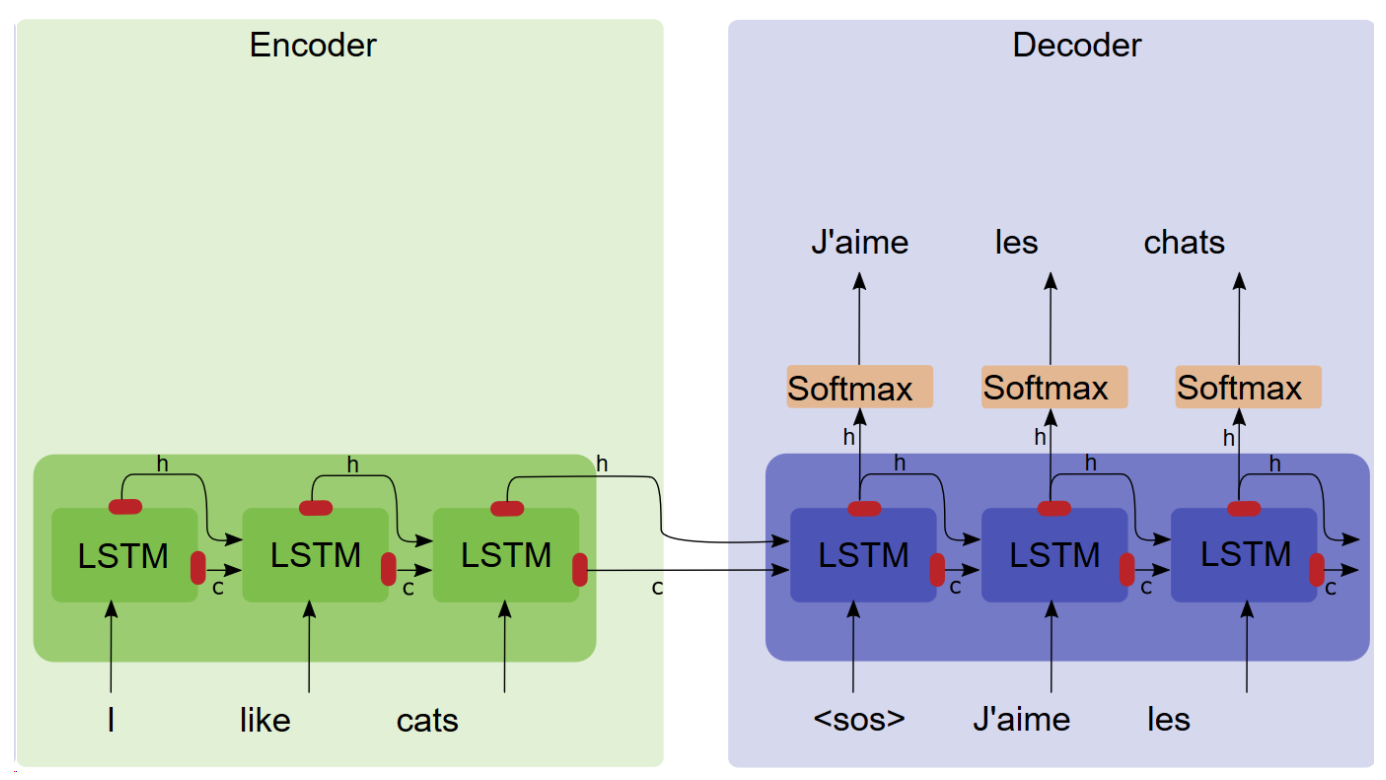
加性注意力来自于论文《Neural Machine Translation By Jointly Learning to Align and Translate》[1],又称为Bahdanau Attention,在论文中应用于机器翻译任务。在介绍Bahdanau Attention前,我们先来看一下LSTM以及普通的Encoder-Decoder的计算过程。
LSTM计算过程
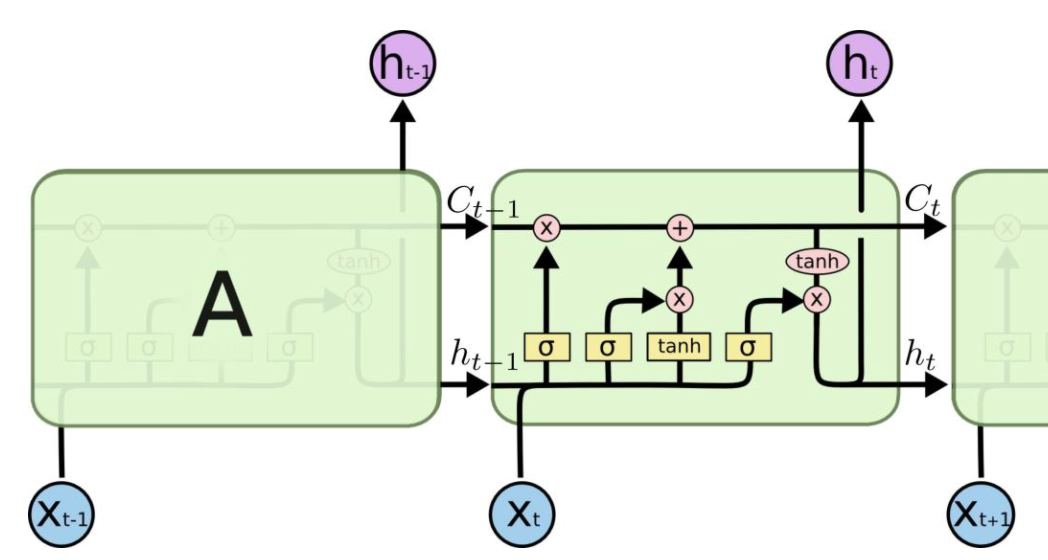
传统的DNN的隐节点可以表示为$h_{t}=\sigma\left(x_{t} \times w_{x t}+b\right)$,而普通RNN的隐节点可以表示为$h_{t}=\sigma\left(x_{t} \times w_{x t}+h_{t-1} \times w_{h t}+b\right)$,因此RNN的隐节点$h_{t-1}$有两个作用:
- 计算在该时刻的预测值:$\hat{y}_{t}=\sigma\left(h_{t} * w+b\right)$
- 计算下个时间片的隐节点状态:$h_t$
LSTM在计算h_t时增加门控机制:
- $f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)$
- $i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right)$
- $\tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)$
- $h_{t}=o_{t} * \tanh \left(C_{t}\right)$
GRU计算过程
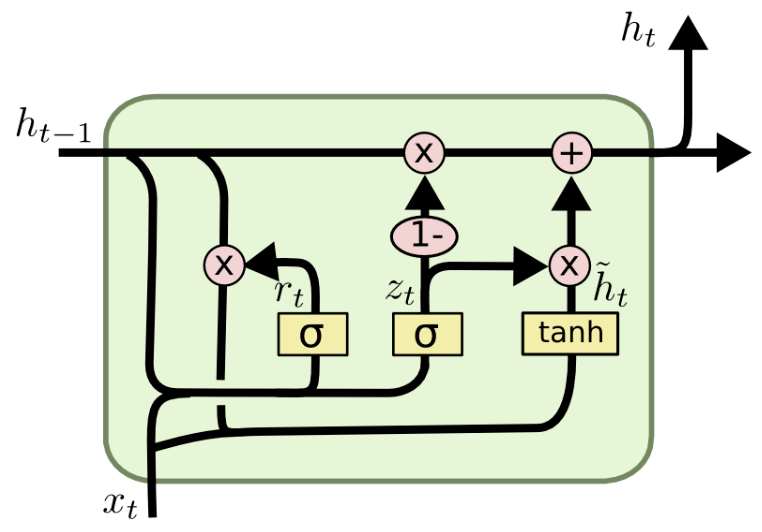
- $z_{t}=\sigma\left(W_{z} \cdot\left[h_{t-1}, x_{t}\right]\right)$
- $r_{t}=\sigma\left(W_{r} \cdot\left[h_{t-1}, x_{t}\right]\right)$
- $\tilde{h}_{t}=\tanh \left(W \cdot\left[r_{t} * h_{t-1}, x_{t}\right]\right)$
- $h_{t}=\left(1-z_{t}\right) h_{t-1}+z_{t} \tilde{h}_{t}$
Encoder-Decoder计算过程
Bahdanau Attention
加性模型的表达式:$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=v^{T} \tanh \left(\mathbf{W} \mathbf{x}_{\mathbf{i}}+\mathbf{U q}\right)$,加性Attention并行不大容易实现(或者实现起来占用显存多),所以一般只用来将变长向量序列编码为固定长度的向量(取代简单的Pooling),而很少用来做序列到序列的编码。
Encoder-Decoder with Bahdanau Attention
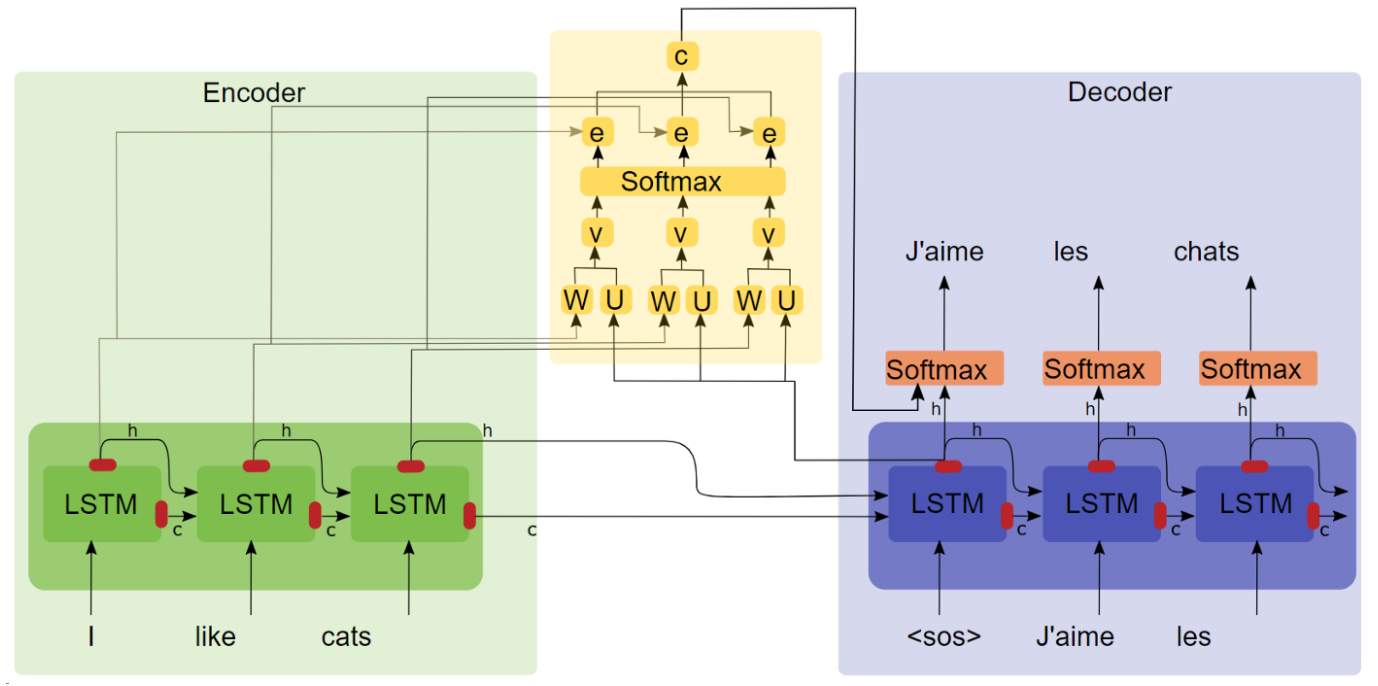
- Encoder
- $h_{i}=\tanh \left(W\left[h_{i-1}, x_{i}\right]\right)$
- $o_{i}=\operatorname{softmax}\left(V h_{i}\right)$
- Decoder
- 生成该时刻的语义向量
- $e_{t i}=v_{a}^{\top} \tanh \left(W_{a}\left[s_{i-1}, h_{i}\right]\right)$:Encoder中第 i 时刻 Encoder隐层状态 $h_i$ 对Decoder中 $t$ 时刻隐层状态 $s_t$ 的影响程度
- $\alpha_{t i}=\frac{\exp \left(e_{t i}\right)}{\sum_{k=1}^{T} \exp \left(e_{t k}\right)}$:对$e_{ti}$的softmax归一化
- $c_{t}=\sum_{i=1}^{T} \alpha_{t i} h_{i}$
- 传递隐层信息并预测
- $s_{t}=\tanh \left(W\left[s_{t-1}, y_{t-1}, c_{t}\right]\right)$
- $o_{t}=\operatorname{softmax}\left(V s_{t}\right)$
- 生成该时刻的语义向量
相关代码可参考:https://github.com/majing2019/keras_bahdanau
双线性注意力
双线性注意力来自于论文《Effective Approaches to Attention-based Neural Machine Translation》,又叫做Luong Attention。与Bahdanau Attention不同之处在于Decoder部分,其计算表达式为$h_{t}^{T} W_{a} \bar{h}_{s}$,使用双线性注意力的机器翻译模型计算过程如下:
- Encoder:和Bahdanau Attention一样
- Decoder
- 生成该时刻的语义向量
- $s_{t}=\tanh \left(W\left[s_{t-1}, y_{t-1}\right]\right)$
- $e_{t i}=s_{t}^{\top} W_{a} h_{i}$
- $\alpha_{t i}=\frac{\exp \left(e_{t i}\right)}{\sum_{k=1}^{T} \exp \left(e_{t k}\right)}$
- $c_{t}=\sum_{i=1}^{T} \alpha_{t i} h_{i}$
- 传递隐层信息并预测
- $\tilde{s}_{t}=\tanh \left(W_{c}\left[s_{t}, c_{t}\right]\right)$
- $o_{t}=\operatorname{softmax}\left(V \tilde{s}_{t}\right)$
- 生成该时刻的语义向量
代码参考:https://github.com/asmekal/keras-monotonic-attention/blob/master/attention_decoder.py
点击注意力
点击注意力来自于论文《Attention Is All You Need》,其表达式为$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=\mathbf{x}_{i}^{T} \mathbf{q}$,也有进行缩放的点击注意力,表达式为$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=\frac{\mathbf{x}_{i}^{\mathrm{T}} \mathbf{q}}{\sqrt{d}}$,点击注意力易于并行实现。下面我们介绍一下Attention的通用表示,顺便理解点击注意力模型。
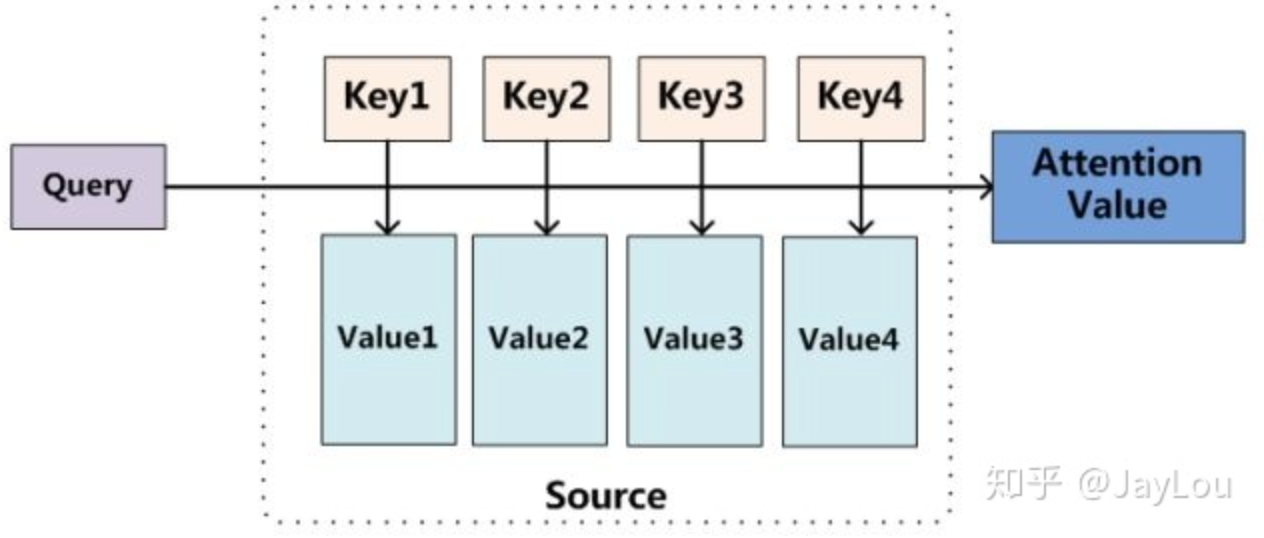
Attention机制的实质其实就是一个寻址(addressing)的过程,如下图所示:给定一个和任务相关的查询Query向量 q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。

点击注意力的计算也可以分为3步,一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均:
- 信息输入:用X = [x1, · · · , xN ]表示N 个输入信息
- 注意力分布计算:令Key=Value=X,则可以给出注意力分布$\alpha_{i}=\operatorname{softmax}\left(s\left(k e y_{i}, q\right)\right)=\operatorname{softmax}\left(s\left(X_{i}, q\right)\right)$
- 我们将$\alpha_{i}$称之为注意力分布,$s\left(X_{i}, q\right)$为注意力打分机制,有几种打分机制
- 加性模型:$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=\mathbf{v}^{\mathrm{T}} \tanh \left(W \mathbf{x}_{i}+U \mathbf{q}\right)$
- 点击模型:$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=\mathbf{x}_{i}^{\mathrm{T}} \mathbf{q}$
- 缩放点击模型:$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=\frac{\mathbf{x}_{i}^{\mathrm{T}} \mathbf{q}}{\sqrt{d}}$
- 双线性模型:$s\left(\mathbf{x}_{i}, \mathbf{q}\right)=\mathbf{x}_{i}^{\mathrm{T}} W \mathbf{q}$
- 我们将$\alpha_{i}$称之为注意力分布,$s\left(X_{i}, q\right)$为注意力打分机制,有几种打分机制
- 信息加权平均:注意力分布$\alpha_{i}$可以解释为在上下文查询q时,第i个信息受关注的程度,采用一种“软性”的信息选择机制对输入信息X进行编码为:$\operatorname{att}(q, X)=\sum_{i=1}^{N} \alpha_{i} X_{i}$
- 这种编码方式为软性注意力机制(soft Attention),软性注意力机制有两种:普通模式(Key=Value=X)和键值对模式(Key!=Value),如下图中的左图和右图
注意力机制变体
Attention上的变种主要有3种:
- 硬性注意力:之前提到的注意力是软性注意力,其选择的信息是所有输入信息在注意力分布下的期望。还有一种注意力是只关注到某一个位置上的信息,叫做硬性注意力(hard attention)。硬性注意力有两种实现方式:
- 一种是选取最高概率的输入信息;
- 另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现。
- 硬性注意力模型的缺点:
- 硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。硬性注意力需要通过强化学习来进行训练。
- 键值对注意力:即上面说的Key!=Value
- 多头注意力:多头注意力(multi-head attention)是利用多个查询Q = [q1, · · · , qM],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接:$\operatorname{att}((K, V), Q)=\operatorname{att}\left((K, V), \mathbf{q}_{1}\right) \oplus \cdots \oplus \operatorname{att}\left((K, V), \mathbf{q}_{M}\right)$
- 自注意力:self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部,具体代码可参考:https://cloud.tencent.com/developer/article/1451523
下面会依据一些论文罗列一些注意力的变体。
自注意力
传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端的每个词与目标端每个词之间的依赖关系。但Self Attention不同,它分别在source端和target端进行,仅与source input或者target input自身相关的Self Attention,捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端词与词之间的依赖关系。因此,self Attention Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention可以不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。
Sentence Embedding
在论文《A Structured Self-attentive Sentence Embedding》中使用了self-attention。 现有的处理文本的常规流程第一步就是Word embedding,也有一些 embedding 的方法是考虑了 phrase 和 sentences 的。这些方法大致可以分为两种: universal sentence(general 的句子)和 certain task(特定的任务)。常规的做法是利用 RNN 最后一个隐层的状态,或者 RNN hidden states 的 max or average pooling 或者 convolved n-grams,也有一些工作考虑到解析和依赖树(parse and dependence trees)。
对于一些工作,人们开始考虑通过引入额外的信息,用 attention 的思路,以辅助 sentence embedding。但是对于某些任务,如情感分类,并不能直接使用这种方法,因为并没有此类额外的信息。此时,最常用的做法就是 max pooling or averaging 所有的 RNN 时间步骤的隐层状态,或者只提取最后一个时刻的状态作为最终的 embedding。
而本文提出一种 self-attention 的机制来替换掉通常使用的 max pooling or averaging step。不同于前人的方法,本文所提出的 self-attention mechanism 允许提取句子的不同方便的信息,来构成多个向量的表示。在我们的句子映射模型中,是在 LSTM 的顶端执行的。这确保了 attention 模型可以应用于没有额外信息输入的任务当中,并且减少了 lstm 的一些长期记忆负担。另外一个好处是,可视化提取embedding 变的非常简单和直观,模型结构如下:
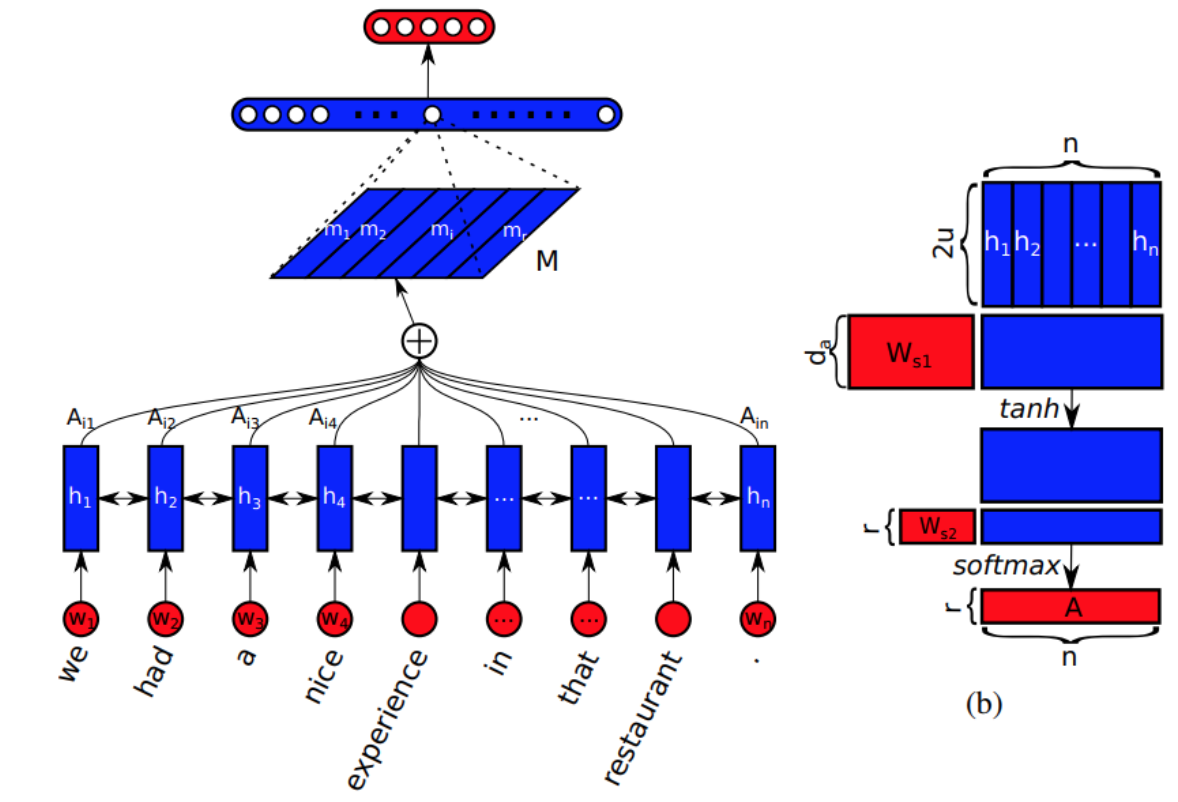
模型的计算过程如下:
- 给定一个句子,我们首先将其进行 Word embedding,得到:S = (w1, w2, … , wn),然后讲这些 vector 拼成一个 2-D 的矩阵,维度为[n, d]
- 用双向 lstm 来建模,得到其两个方向的隐层状态,然后,此时我们可以得到维度为[n, 2*u],记为H
- 为了将变长的句子,编码为固定长度的 embedding。论文通过选择 n 个 LSTM hidden states 的线性组合,来达到这一目标。计算这样的线性组合,需要利用 self-attention 机制,该机制将 lstm 的所有隐层状态 H 作为输入,并且输出为一个向量权重$\mathbf{a}=\operatorname{softmax}\left(\mathbf{w}_{\mathbf{s} \mathbf{2}} \tanh \left(W_{s 1} H^{T}\right)\right)$,其中W_{s1}维度是[d_a, 2*u],w_{s2}是大小为d_a的向量
- 将 lstm 的隐层状态 H 和 attention weight a 进行加权,即可得到 attend 之后的向量 m
- 为了表示句子的总体的语义,需要多个 m 来聚焦于不同的部分。所以,需要用到multiple hops of attention,即想从句子中提取出 r 个不同的部分。论文将w_{s2}拓展为[r, d_a]的矩阵,记为W_{s2},使得向量a变为矩阵A,即$A=\operatorname{softmax}\left(W_{s 2} \tanh \left(W_{s 1} H^{T}\right)\right)$,此时softmax是沿着输入的 第二个维度执行的,我们也可以把它看成是没有bias的2层的MLP。映射向量 m 然后就变成了[r, 2*u]的矩阵,我们通过将 annotation A 和 lstm 的隐层状态 H 进行相乘,得到的结果矩阵就是句子的映射M=AH
代码参考:https://github.com/chaitjo/structured-self-attention
键值注意力
Transformer中使用呢了键值注意力,这里我们介绍一些其他论文中出现的key-value attention。
Neural Language Modeling
在论文《Frustratingly Short Attention Spans in Neural Language Modeling》中使用了键值注意力进行语言模型建模。作者首先将注意力机制拆分为三部分:
- keys: 对比当前时刻的状态和过去时刻的状态
- values: 比较结果用于建模上下文
- prediction: 综合当前时刻和上下文的信息来进行预测
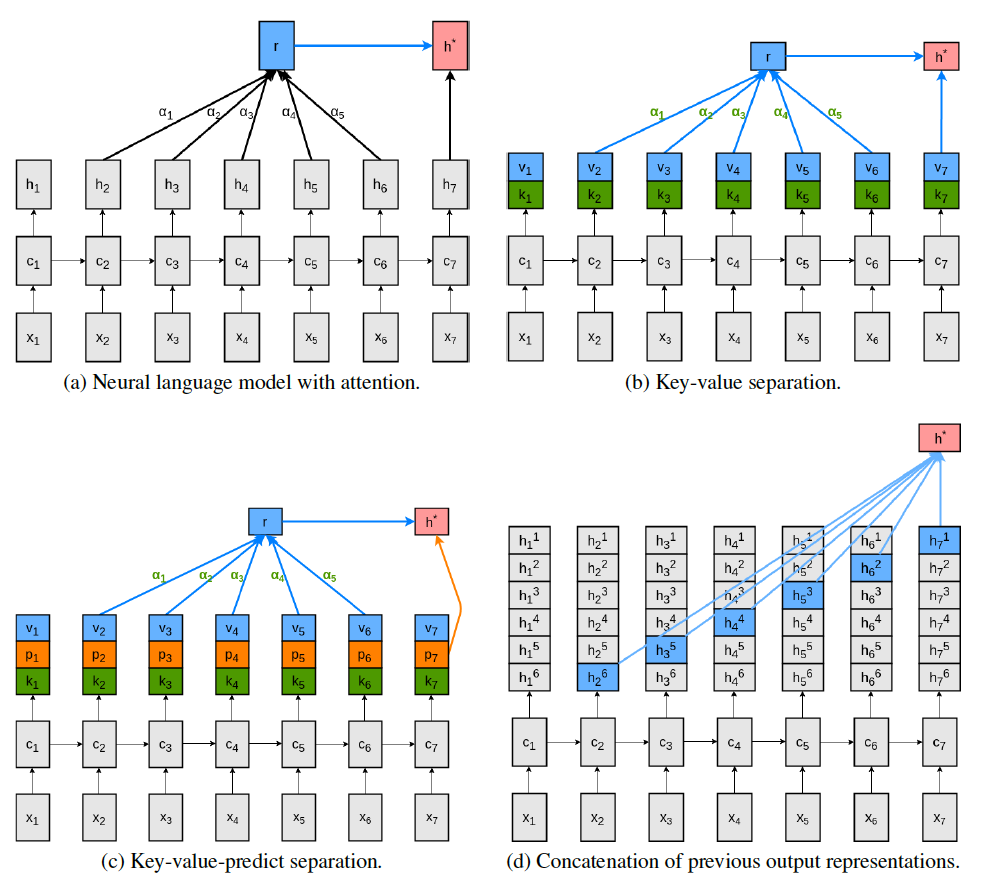
对比上图中的 (a) 和 (b),可以看到,作者将解码器状态 $h_i$ 拆分为 $k_i$ 和$v_i$,并用 $k_i$ 比较每一个时刻的解码器状态,用得到的 $v_i$ 建模上下文和预测下一个词。这就是作者提出的第一个改进模型,key-value attention model。
显然,这个模型中,$v_i$ 仍然一人分饰两角。所以作者进一步提出了第二个改进模型,key-value-predict attention model:将解码器状态拆分为三个向量,其中新引入的 $p_i$ 用于做预测。这个模型示意图请参考图 (c)。
在实验中,作者提出的两个改进模型在大部分数字指标下的表现,都超过了传统注意力机制模型,并且符合预期地:key-value-predict attention > key-value attention > traditional attention。然而,从可视化的结果来看,这些模型的差异却并没有那么大:
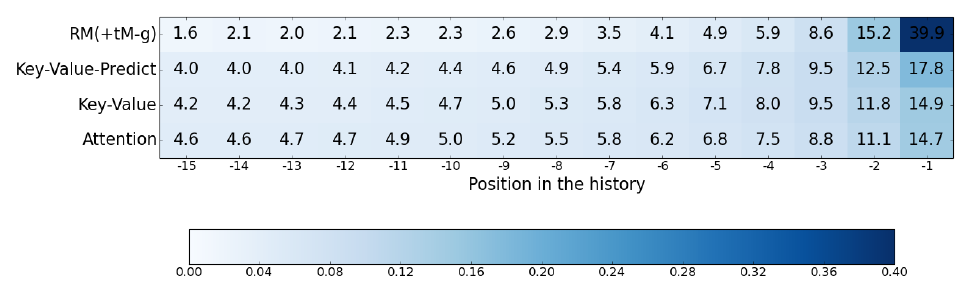
作者发现,这些基于注意力机制的模型的注意力基本都局限在最近的5个状态的窗口里,也就是题目中所谓的 short span。这也直接导致了,当作者用基于 N-gram 的 RNN 代替基于注意力机制的 RNN 时,也取得了非常惊人的表现。作者也通过改变注意力窗口大小,再次印证了,注意力机制的局限性。当窗口增大到一定程度,也就是注意力范围扩大到一定程度后,实验结果并不会继续提高了。换句话说,注意力机制对于捕捉 long-term 范围内的信息的帮助很小。
相对位置自注意力
不同于卷积网络或循环网络,Transformer结构中并不明确地建模(输入字符的)相对或绝对信息。相反,其需要向输入中添加绝对位置表示。在论文《Self-Attention with Relative Position Representations》中提出了一种可供选择的方法来扩展self-attention机制,使其能够高效地考虑到序列元素之间的相对位置或距离。
对于一个输入序列 “I BELIEVE THAT I CAN DO IT”,如果不添加位置信息,那么transformer模型是无法感知序列中的两个 “I” 的先后关系。 常见的做法是输入序列的词嵌入(Word Embedding)上加上位置编码(Position Encodings),这些位置编码可以是随时间变化的函数或者是可训练的参数(例如$P E_{(\text {pos }, 2 i)}=\sin \left(\text { pos } / 10000^{2 i / d_{\text {model }}}\right)$、$P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right)$)。
Transformer模型中注意力计算形式为$\text { attn }=\text { Attention }\left(X W^{Q}, X W^{K}, X W^{V}\right)$,其中表$X=X_{E}+X_{P}$示输入序列的WordEmbedding和PositionEncodings之和,在Attention函数中主要利用位置编码的地方在于计算AttnScore,而计算AttnScore的核心公式为:$\text { scores }=\left(X W^{Q}\right)\left(X W^{K}\right)^{T}=X W^{Q}\left(W^{K}\right)^{T} X^{T}$,经过变$W^{Q}\left(W^{K}\right)^{T}$换之后,位置编码信息会有所缺失。论文从结构上对AttentionMechanism进行改变,提出相对感知的注意力机制(Relation−aware Self−Attention)。
我们以one-head的self-attention为例进行介绍。Self-attention的输入为$x=\left(x_{1}, \ldots, x_{n}\right), x_{i} \in \mathbb{R}^{d_{x}}$,输出为,$z=\left(z_{1}, \ldots, z_{n}\right), z_{i} \in \mathbb{R}^{d_{z}}$每个z_i的计算公式为$z_{i}=\sum_{j=1}^{n} \alpha_{i j}\left(x_{j} W^{V}\right)$,参数的$\alpha_{i j}$计算公式为$\alpha_{i j}=\frac{\exp e_{i j}}{\sum_{k=1}^{n} \exp e_{i k}}$,而$e_{i j}$的计算公式为$e_{i j}=\frac{\left(x_{i} W^{Q}\right)\left(x_{j} W^{K}\right)^{T}}{\sqrt{d_{z}}}$,其中$W^{Q}, W^{K}, W^{V} \in \mathbb{R}^{d_{x} \times d_{z}}$为参数矩阵,用图表示如下:
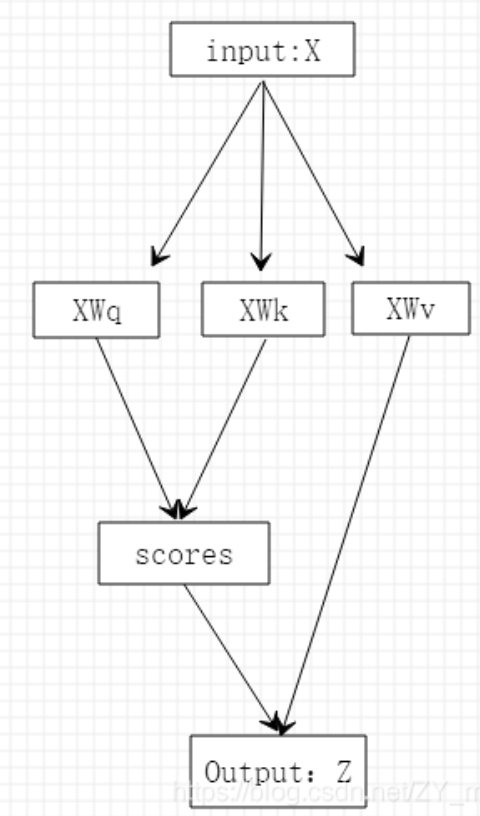
为了在计算attention-score时加入位置信息,作者将输入序列之间的关系视为带标记的全连接有向图。输入序列中两个元素x_i和x_j之间的边表示为$\alpha_{i j}^{V}, \alpha_{i j}^{K} \in \mathbb{R}^{d_{a}}$,并将其加入以下两个式子中:$z_{i}=\sum_{j=1}^{n} \alpha_{i j}\left(x_{j} W^{V}+\alpha_{i j}^{V}\right)$、$e_{i j}=\frac{x_{i} W^{Q}\left(x_{j} W^{K}+\alpha_{i j}^{K}\right)^{T}}{\sqrt{d_{z}}}$。参数$\alpha_{i j}^{V}, \alpha_{i j}^{K} \in \mathbb{R}^{d_{a}}$在每个head和一个sequence之间共享且$d_{a}=d_{z}$。序列中两个位置i、j之间相对位置信息参数表示为$\alpha_{i j}^{V}=w_{j-i}^{V}, \alpha_{i j}^{K}=w_{j-i}^{K}$,序列元素之间的相对位置关系图如下所示:
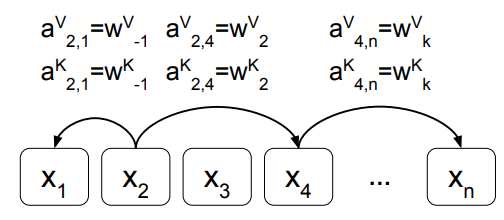
论文假设序列中两个元素之间的相对位置超过一定距离k之后就不再有用。因而对于每个元素x_i,只考虑其2k+1个相对位置的元素,公式上表示如下:
$\begin{aligned}
a_{i j}^{K} &=w_{\mathrm{clip}(j-i, k)}^{K} \\
a_{i j}^{V} &=w_{\operatorname{clip}(j-i, k)}^{V} \\
\operatorname{clip}(x, k) &=\max (-k, \min (k, x))
\end{aligned}$
其中$w^{K}=\left(w_{-k}^{K}, \ldots, w_{k}^{K}\right), w^{V}=\left(w_{-k}^{V}, \ldots, w_{k}^{V}\right)$并且$w_{i}^{K}, w_{i}^{V} \in \mathbb{R}^{d_{a}}$,对于上式中的clip函数,能够将相对距离限制在[-k, k]内(符号表示方向)。用分段函数表示clip函数更为直观,如下:
$\operatorname{clip}(x, k)=\left\{\begin{array}{ll}
-k & , x \leq-k \\
x & ,-k<x<k \\
k & , x \geq k
\end{array}\right.$
代码参考:https://github.com/tensorflow/tensor2tensor
层次注意力
层级“注意力”网络的网络结构如下图所示,网络可以被看作为两部分,第一部分为词“注意”部分,另一部分为句“注意”部分。整个网络通过将一个句子分割为几部分,对于每部分,都使用双向RNN结合“注意力”机制将小句子映射为一个向量,然后对于映射得到的一组序列向量,我们再通过一层双向RNN结合“注意力”机制实现对文本的分类。
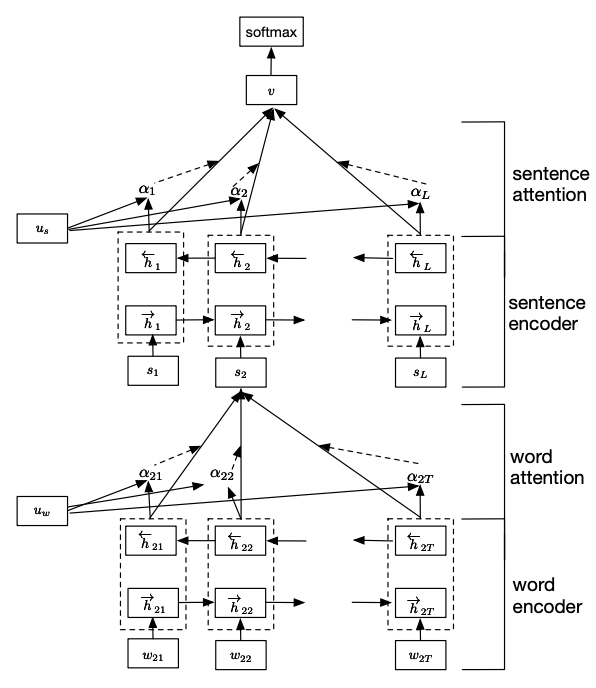
论文针对的是任务是文档分类任务,即认为每个要分类的文档都可以分为多个句子。因此层级“注意力”模型的第一部分是来处理每一个分句。对于第一个双向RNN输入是每句话的每个单词w_{it},其计算公式如下:
- $x_{i t}=W_{e} w_{i t}, t \in[1, T]$
- $\vec{h}_{i t}=\overrightarrow{\operatorname{GRU}}\left(x_{i t}\right), t \in[1, T]$
- $\overleftarrow{h}_{i t}=\overleftarrow{\operatorname{GRU}}\left(x_{i t}\right), t \in[T, 1]$
- $h_{i t}=\left[\vec{h}_{i t}, \stackrel{\leftarrow}{h}_{i t}\right]$
其中$w_{it}$表示单词,$W_e$是词向量矩阵,GRU的计算过程如下:
- $r_{t}=\sigma\left(W_{r} x_{t}+U_{r} h_{t-1}+b_{r}\right)$,$r_t$是遗忘门,决定留下多少历史信息,如果$r_t$为0表示不保留历史信息
- $\tilde{h}_{t}=\tanh \left(W_{h} x_{t}+r_{t} \odot\left(U_{h} h_{t-1}\right)+b_{h}\right)$
- $z_{t}=\sigma\left(W_{z} x_{t}+U_{z} h_{t-1}+b_{z}\right)$,$z_t$控制历史信息和当前信息的保留比例
- $h_{t}=\left(1-z_{t}\right) \odot h_{t-1}+z_{t} \odot \tilde{h}_{t}$
对于一句话中的单词,并不是每一个单词对分类任务都是有用的,比如在做文本的情绪分类时,可能我们就会比较关注“很好”、“伤感”这些词。为了能使循环神经网络也能自动将“注意力”放在这些词汇上,论文设计了基于单词的注意力模型,其计算公式如下:
- $u_{i t}=\tanh \left(W_{w} h_{i t}+b_{w}\right)$
- $\alpha_{i t}=\frac{\exp \left(u_{i t}^{\top} u_{w}\right)}{\sum_{t} \exp \left(u_{i t}^{\top} u_{w}\right)}$
- $s_{i}=\sum_{t} \alpha_{i t} h_{i t}$
通过一个线性层对双向RNN的输出进行变换,然后通过softmax公式计算出每个单词的重要性,最后通过对双向RNN的输出进行加权平均得到每个句子的表示。
句层面的“注意力”模型和词层面的“注意力”模型有异曲同工之妙。其计算公式如下所示:
- $\vec{h}_{i}=\overrightarrow{\operatorname{GRU}}\left(s_{i}\right), i \in[1, L]$
- $\overleftarrow{h}_{i}=\overleftarrow{\operatorname{GRU}}\left(s_{i}\right), t \in[L, 1]$
- $h_{i}=\left[\vec{h}_{i}, \overleftarrow{h}_{i}\right]$
- $u_{i}=\tanh \left(W_{s} h_{i}+b_{s}\right)$
- $\alpha_{i}=\frac{\exp \left(u_{i}^{\top} u_{s}\right)}{\sum_{i} \exp \left(u_{i}^{\top} u_{s}\right)}$
- $v=\sum_{i} \alpha_{i} h_{i}$
最后就是使用最常用的softmax分类器对整个文本进行分类了:$p=\operatorname{softmax}\left(W_{c} v+b_{c}\right)$,损失函数为:$L=-\sum_{d} \log p_{d j}$。
稀疏注意力
从理论上来讲,Self Attention的计算时间和显存占用量都是$O(n^2)$级别的(n是序列长度),这就意味着如果序列长度变成原来的2倍,显存占用量就是原来的4倍,计算时间也是原来的4倍。当然,假设并行核心数足够多的情况下,计算时间未必会增加到原来的4倍,但是显存的4倍却是实实在在的,无可避免,这也是微调Bert的时候时不时就来个OOM的原因了。
我们说Self Attention是$O(n^2)$的,那是因为它要对序列中的任意两个向量都要计算相关度,得到一个$n^2$大小的相关度矩阵:
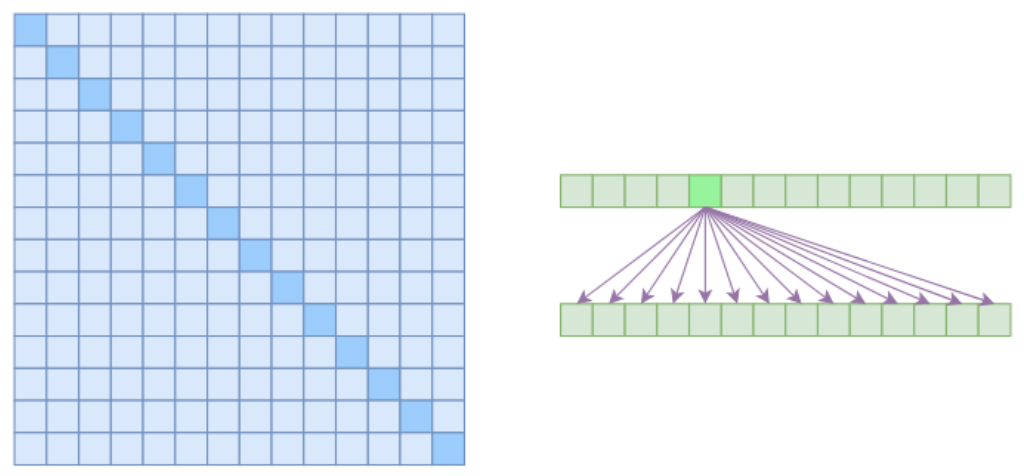
在上图中,左边显示了注意力矩阵,右变显示了关联性,这表明每个元素都跟序列内所有元素有关联。所以,如果要节省显存,加快计算速度,那么一个基本的思路就是减少关联性的计算,也就是认为每个元素只跟序列内的一部分元素相关,这就是稀疏Attention的基本原理。
Atrous Self Attention
Atrous Self Attention的中文可以称之为“膨胀自注意力”、“空洞自注意力”、“带孔自注意力”等。Atrous Self Attention就是启发于“膨胀卷积(Atrous Convolution)”,如下右图所示,它对相关性进行了约束,强行要求每个元素只跟它相对距离为k,2k,3k,…的元素关联,其中k>1是预先设定的超参数。从下左的注意力矩阵看,就是强行要求相对距离不是k的倍数的注意力为0(白色代表0):
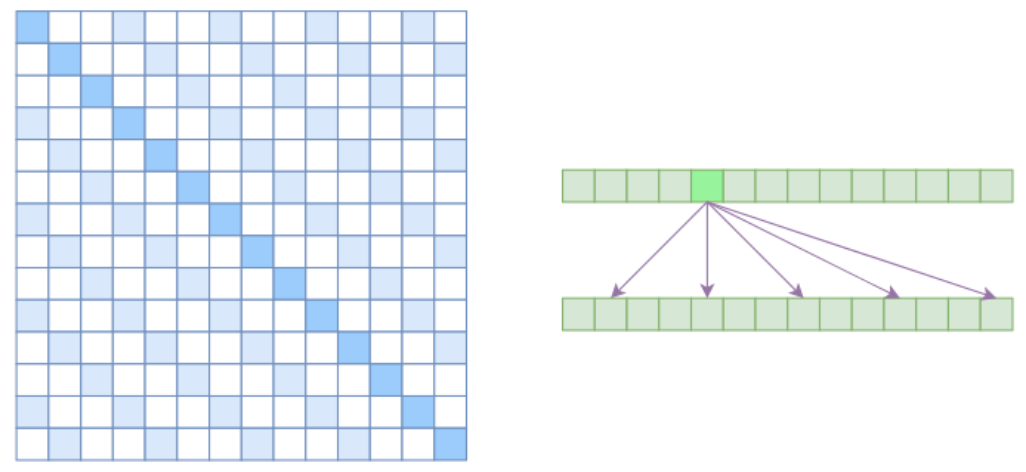
由于现在计算注意力是“跳着”来了,所以实际上每个元素只跟大约n/k个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了$O(n^2/k)$,也就是说能直接降低到原来的1/k。
Local Self Attention
Local Self Attention中文可称之为“局部自注意力”。其实自注意力机制在CV领域统称为“Non Local”,而显然Local Self Attention则要放弃全局关联,重新引入局部关联。具体来说也很简单,就是约束每个元素只与前后k个元素以及自身有关联,如下图所示:
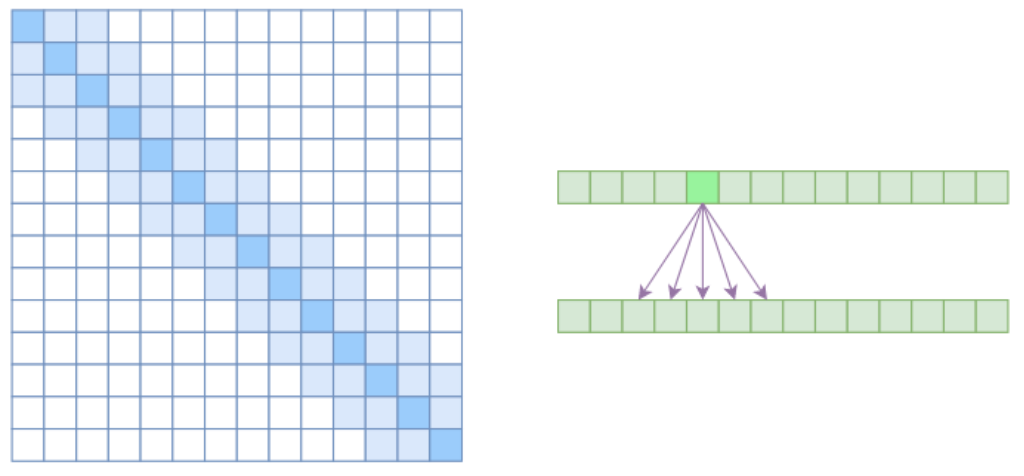
从注意力矩阵来看,就是相对距离超过k的注意力都直接设为0。其实Local Self Attention就跟普通卷积很像了,都是保留了一个2k+1大小的窗口,然后在窗口内进行一些运算,不同的是普通卷积是把窗口展平然后接一个全连接层得到输出,而现在是窗口内通过注意力来加权平均得到输出。对于Local Self Attention来说,每个元素只跟2k+1个元素算相关性,这样一来理想情况下运行效率和显存占用都变成了O((2k+1)n)∼O(kn)了,也就是说随着n而线性增长,这是一个很理想的性质——当然也直接牺牲了长程关联性。
Sparse Self Attention
论文《Generating Long Sequences with Sparse Transformers》直接将两个Atrous Self Attention和Local Self Attention合并为一个,如下图:
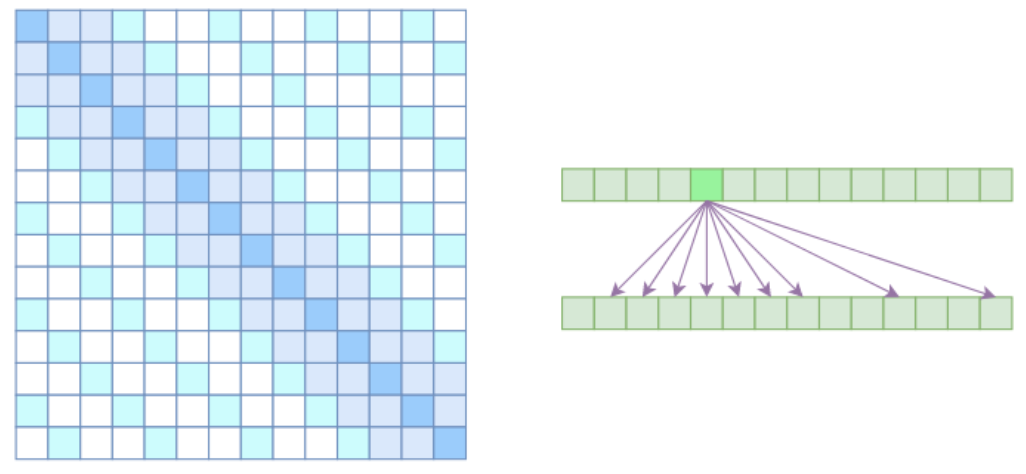
从注意力矩阵上看就很容易理解了,就是除了相对距离不超过k的、相对距离为k,2k,3k,…的注意力都设为0,这样一来Attention就具有“局部紧密相关和远程稀疏相关”的特性,这对很多任务来说可能是一个不错的先验,因为真正需要密集的长程关联的任务事实上是很少的。
线性注意力
传统的Transformer Attention形式为:$\text { Attention }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\boldsymbol{Q K}^{\top}\right) \boldsymbol{V}$,其中,$\boldsymbol{Q} \in \mathbb{R}^{n \times d_{k}}, \boldsymbol{K} \in \mathbb{R}^{m \times d_{k}}, \boldsymbol{V} \in \mathbb{R}^{m \times d_{v}}$。在Self Attention场景下,为了介绍上的方便统一设,$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V} \in \mathbb{R}^{n \times d}$,一般场景下都有n>d甚至n>>d。
制约Attention性能的关键因素,其实是定义里边的Softmax:QK^T这一步我们得到一个n^2的矩阵,就是这一步决定了Attention的复杂度是$O(n^2)$,如果没有Softmax,那么就是三个矩阵连乘$QK^TV$,而矩阵乘法是满足结合率的,所以我们可以先算$K^TV$,得到一个$d^2$的矩阵,然后再用Q左乘它,由于d<<n,所以这样算大致的复杂度只是O(n)。也就是说,去掉Softmax的Attention的复杂度可以降到最理想的线性级别O(n)!
问题是,直接去掉Softmax还能算是Attention吗?它还能有标准的Attention的效果吗?为了回答这个问题,我们先将Scaled-Dot Attention的定义等价地改写为:
$\text { Attention }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_{i}=\frac{\sum_{j=1}^{n} e^{\boldsymbol{q}_{i}^{\top} \boldsymbol{k}_{j} \boldsymbol{v}_{j}}}{\sum_{j=1}^{n} e^{\boldsymbol{q}_{i}^{\top} \boldsymbol{k}_{j}}}$
所以,Scaled-Dot Attention其实就是以$e^{\boldsymbol{q}_{i}^{\top} \boldsymbol{k}_{j}}$为权重对$v_j$做加权平均。所以我们可以提出一个Attention的一般化定义:
$\text { Attention }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})_{i}=\frac{\sum_{j=1}^{n} \operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right) \boldsymbol{v}_{j}}{\sum_{j=1}^{n} \operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)}$
也就是把$e^{\boldsymbol{q}_{i}^{\top} \boldsymbol{k}_{j}}$换成的$\boldsymbol{q}_{i}, \boldsymbol{k}_{j}$一般函数$\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)$,为了保留Attention相似的分布特性,我们要求$\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right) \geq 0$恒成立。也就是说,我们如果要定义新式的Attention,那么要保留式上式的形式,并且满足$\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right) \geq 0$。
如果直接去掉Softmax,那么就是$\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)=\boldsymbol{q}_{i}^{\top} \boldsymbol{k}_{j}$,问题是内积无法保证非负性,所以这还不是一个合理的选择。
论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》的想法是:如果q_i、k_j的每个元素都是非负的,那么内积自然也就是非负的。为了完成这点,可以给q_i、k_j各自加值域非负的激活函数$\phi, \varphi$,即$\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)=\phi\left(\boldsymbol{q}_{i}\right)^{\top} \varphi\left(\boldsymbol{k}_{j}\right)$。论文选择的是$\phi(x)=\varphi(x)=\operatorname{elu}(x)+1$。
论文《Efficient Attention: Attention with Linear Complexities》则给出了一个更有意思的选择:它留意到在$QK^T$中,$\boldsymbol{Q}, \boldsymbol{K}, \in \mathbb{R}^{n \times d}$,如果“Q在d那一维是归一化的、并且K在n那一维是归一化的”,那么QK^T就是自动满足归一化了,所以它给出的选择是:$\text { Attention }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}_{2}(\boldsymbol{Q}) \operatorname{softmax}_{1}(\boldsymbol{K})^{\top} \boldsymbol{V}$。其中softmax1、softmax2分别指在第一个(n)、第二个维度(d)进行Softmax运算。也就是说,这时候我们是各自给Q,K加Softmax,而不是QK^T算完之后才加Softmax。其实可以证明这个形式也是的$\operatorname{sim}\left(\boldsymbol{q}_{i}, \boldsymbol{k}_{j}\right)=\phi\left(\boldsymbol{q}_{i}\right)^{\top} \varphi\left(\boldsymbol{k}_{j}\right)$一个特例,此时对应于$\phi\left(\boldsymbol{q}_{i}\right)=\operatorname{softmax}\left(\boldsymbol{q}_{i}\right), \varphi\left(\boldsymbol{k}_{j}\right)=e^{k j}$。
类似的论文还有《Rethinking Attention with Performers》、《Linformer: Self-Attention with Linear Complexity》等,其中第二篇论文还是借鉴了CV领域的《Expectation-Maximization Attention Networks for Semantic Segmentation》。
基于距离自注意力
论文《Distance-based Self-Attention Network for Natural Language Inference》上做了微创新, 使用 distance mask, 对相对位置进行了建模, 相距越远的单词, mask matrix 中对应位置将是一个越大的负值, 从而一定程度上抑制了远距离单词间的依赖, 换言之, 强调了单词对邻近单词的依赖, 从而更好地分配 attention。
文章将提出的模型应用于自然语言推理 NLI, 沿用了传统框架 (如下), 创新点体现在 sentence encoder上:
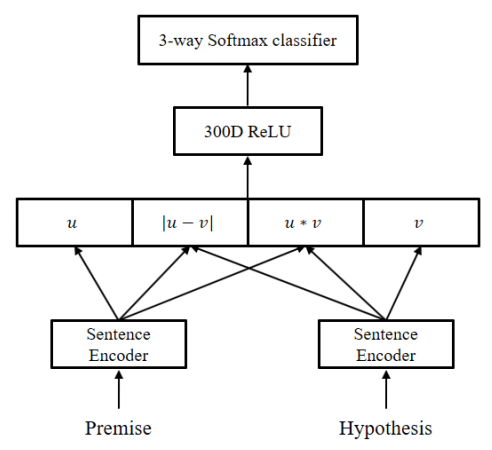
sentence encoder 基于 self-attention 对句子进行编码 (如下), 可以看到中间那一部分像极了 Transformer 的 encoder. 不同点在于, mutl-head attention 带上了 mask, 后一层的 add 变成了 gate:
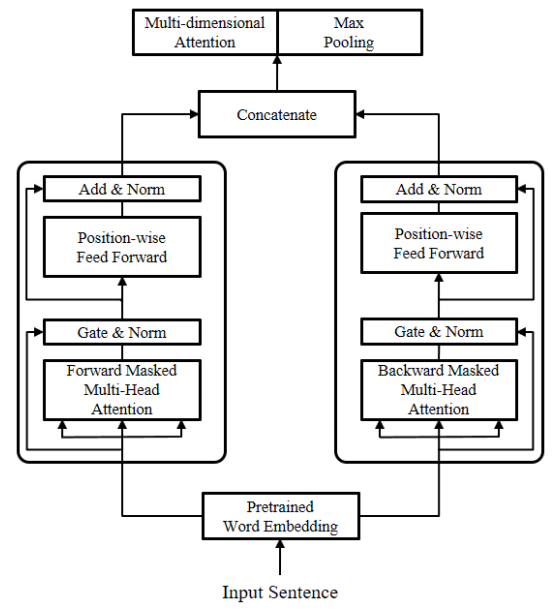
可以看到, 模型从 forward 和 backward 两个方向分别进行了学习, 因此, 即使使用了 distance mask, 也没有抛弃 DiSAN 中提出的 directional mask. Masked Attention 的计算如下:
$\begin{array}{l}
\operatorname{Masked}(Q, K, V) \\
\quad=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}+M_{d i r}+\alpha M_{d i s}\right) V
\end{array}$
Distance mask 中每个元素代表句中两个单词间绝对距离的负. 由于$e^{-inf}=0$,因此距离越远, 负值越大, 单词间的依赖程度越低:
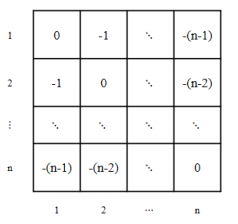
Distance mask 强化单词对邻近单词的依赖, 作用类似于 CNN 的 filter提取局部特征. 不同点在于, 前者是对整个句子的 mask, 而后者仅仅局部像素的 mask。
Masked multi-head attention 之后是一个 Fusion gate, 控制 attention 输出和 word embedding 的比例:$\operatorname{Gate}(S, H)=F \odot S^{F}+(1-F) \odot H^{F}$
其中(S 是 word embedding 的矩阵, H 是 attention 的矩阵,$F=\operatorname{sigmoid}\left(S^{F}+H^{F}+b^{F}\right)$)
最后使用 MaxPooling 或 Multi-dimensional attention 或两者一起, 将拼接结果矩阵压缩为向量。
实验证明:
- 相对位置很重要, 使用 distance mask 的实验组比不使用 distance mask 的实验组对句子长度具有更强的鲁棒性;
- distance mask 强化了单词对邻近单词的依赖, 但真正具有强依赖关系的单词, 在远距离的情况下也能保持依赖. 换言之, 在保证局部依赖的同时, 又不失全局依赖.
- Fusion gate 具有调节输出的作用, 关键词将更多地从 attention 输出, 非关键词更多地走 shortcut connection, 保持 word embedding.
- Multi-dimensional attention 与 max pooling 的行为很相似, 都更关注关键词.
全局和局部注意力
在论文《Effective Approaches to Attention-based Neural Machine Translation》中,对NMT任务使用的attention机制提出两种结构,global attention将attention作用于全部输入序列,local attention每个时间步将attention作用于输入序列的不同子集。前者被称为soft attention,后者是hard attention和soft attention的结合。
Global Attention
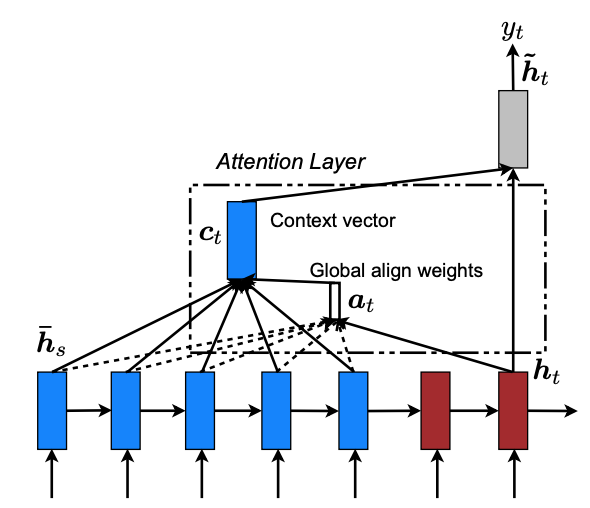
Global Attention考虑Encoder顶层所有的隐藏状态,此时,对齐向量a_t的长度与输入的长度相同,也就是:$a_{t}(s)=\operatorname{align}\left(h_{t}, \bar{h}_{s}\right)=\frac{\exp \left(\operatorname{score}\left(h_{t}, \bar{h}_{\mathrm{s}}\right)\right)}{\sum_{s^{\prime}} \exp \left(\operatorname{score}\left(h_{t}, \bar{h}_{s}\right)\right)}$。
score其实就是计算当前隐层输出与源隐层输出的相似度比对,作者给出了score的三种content-based function:
$\operatorname{score}\left(\boldsymbol{h}_{t}, \overline{\boldsymbol{h}}_{s}\right)=\left\{\begin{array}{ll}
\boldsymbol{h}_{t}^{\top} \overline{\boldsymbol{h}}_{s} & \text { dot } \\
\boldsymbol{h}_{t}^{\top} \boldsymbol{W}_{\boldsymbol{a}} \overline{\boldsymbol{h}}_{s} & \text { general } \\
\boldsymbol{v}_{a}^{\top} \tanh \left(\boldsymbol{W}_{\boldsymbol{a}}\left[\boldsymbol{h}_{t} ; \overline{\boldsymbol{h}}_{s}\right]\right) & \text { concat }
\end{array}\right.$
Local Attention
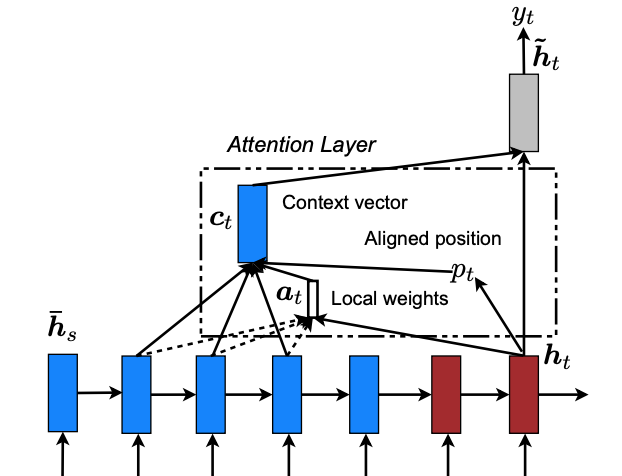
Local Attention是这篇论文的重点部分,首先,Global Attention是有缺陷的,当输入的句子特别长的时候(比如输入是篇章级别的文档),Global Attention的计算量将会变得很大,因为我们要求源句子中所有的词都参与每一时刻的计算,所以作者才提出了Local Attention,即只注意源句子的一个小子集,而不是所有单词,这可以看作是一种软对齐和硬对齐的折中办法,不像软对齐那样注意所有的输入而导致计算量过大,也不像硬对齐那样只选择一个输入而导致过程不可微,需要加入复杂的技巧(variance reduction、reinforcement learning)来训练模型。因此Local Attention既可微,能训练,同时计算量小。
因此,该机制的重点就在于如何寻找与预测词对应的输入隐状态,首先,模型需先生成一个对齐中心 $p_t$(aligned position),在预测输出词的每一时刻,上下文向量 $c_t$ 由窗口 $[p_t - D, p_t + D]$ 中的词导出,这里的 D 是窗口半径,是一个超参数。这样,对齐向量 $a_t$ 是一个定长的向量,长度便为 2D+1,接下来的问题便是,如何确定 $p_t$的值。作者给出了两种确定注意力中心的方法:
- Monotonic alignment:很简单,作者假设输入和输出在很大程度是一一对应的,直接设 $p_t=t$ 就行了,也就是假设输入和输出是单调对齐(Monotonic)的。有了窗口之后,后续步骤就和Global Attention相同了。
- Predictive alignment:不像上面那样假设输入输入单调对齐,而是预测对齐中心$p_{t}=S \cdot \operatorname{sigmoid}\left(\boldsymbol{v}_{p}^{\top} \tanh \left(\boldsymbol{W}_{\boldsymbol{p}} \boldsymbol{h}_{t}\right)\right)$,其中$W_p$、$v_p$为参数,S为源句子的长度,这样就有$p_{t} \in[0, S]$。另外,这里还有一个trick,作者对对齐向量的计算做了修改,作者在$p_t$周围引入了一个服从$N\left(p_{t}, D / 2\right)$的高斯分布来对齐权重,从直觉上考虑,距离目标位置越近的词理当起到更到的作用,因此对齐向量为$\boldsymbol{a}_{t}(s)=\operatorname{align}\left(\boldsymbol{h}_{t}, \overline{\boldsymbol{h}}_{s}\right) \exp \left(-\frac{\left(s-p_{t}\right)^{2}}{2 \sigma^{2}}\right)$,其中$\sigma$也是超参数,作者凭经验选择$\sigma=\frac{D}{2}$。同时也可以看到,在没有引入高斯分布之前,位置$p_t$并没有直接与网络相连,虽然计算$p_t$的过程可以微分,但是作为窗口中心这个操作是不可微的,因此也需要某种额外的方式(用$p_t$来导出$a_t$)将其与网络关联起来,使得参数可以通过backprop训练。
- 可以想下,没有Gassian的引入,是学习不了计算$p_t$中的$W_p$和$v_p$的,因为它不是直接通过某个函数和网络联系起来,而是计算出$p_t$的值,然后把它当做窗口的中心。虽然计算$p_t$的操作可以微分,但是当做窗口中心这个操作是没办法微分的,所以没办法BP。在Hard Attention中,直接取score最大的作为Attention,同理,这个取max的操作无法微分,所以Hard Attention需要使用其他technique来进行优化BP。
基于记忆的注意力
论文《An Introductory Survey on Attention Mechanisms in NLP Problems》对Attention进行了总结,其中包含了Memory-based Attention。
给定存储在 memory 中的键值对$\left\{\left(\mathrm{k}_{\mathrm{i}}, \mathrm{v}_{\mathrm{i}}\right)\right\}$列表和一个查询向量q:
- $e_{i}=a\left(q, k_{i}\right)$(address memory)
- $\alpha_{\mathrm{i}}=\frac{\exp \left(\mathrm{e}_{\mathrm{i}}\right)}{\sum_{\mathrm{i}} \exp \left(\mathrm{e}_{\mathrm{i}}\right)}$(normalize)
- $c=\sum_{i} \alpha_{i} v_{i}$(read contents)
事实上,在很多文献中,“memory”只是输入序列的同义词。注意,如果$k_i$和$v_i$是相同的,则基于记忆的注意力和最基本的注意力是一样的。
但是,由于我们结合了其他功能来实现可重用性和提高灵活性,基于记忆的注意力机制会变得更加强大。
Reusability
在一些问答任务中,一个基本的困难是答案与问题间接相关,因此无法通过基本的注意力技巧轻松解决。然而,如果我们可以通过迭代内存更新(也称为多跳 multi-hop)来逐步引导注意力到答案的正确位置来模拟时间推理过程,就可以实现这一点。直观地说,在每次迭代中,查询都会更新为新内容,而更新后的查询则用于检索相关内容:$q^{(t+1)}=q^{(t)}+c^{(t)}$
更复杂的更新方法包括在多个时间步长的查询和内容之间构建一个循环网络,或根据内容和位置信息进行输出。结果表明,当给出复杂的时间推理任务时,基于记忆的注意模型可以在几次跳跃后成功地找到答案,如下图:

Flexibility
由于键和值被清楚地表示,我们可以自由地将先验知识纳入设计单独的键和值嵌入中,以使它们分别更好地捕获相关信息。具体来说,可以手动设计 key embeddings 来匹配question,而 value embeddings 来匹配响应(response)。在 key-value 记忆网络中,提出了一种窗口级表示形式,以便将 key 构造为围绕 entity tokens 为中心的窗口,而 value 则是那些对应的 entities,旨在实现更有效和准确的匹配。如在 Figure 3 中,“apple” 和 “bedroom” 是 value embeddings,而在它们周围的 tokens 是 key embeddings。
更复杂的结构包括动态记忆网络,整体的结构细分为四个部分:question module、input module、episodic memory module 和 answer module。这种模块化的设计可以实现领域知识的逐段注入、模块之间的有效通信以及对传统问题回答之外的更广泛任务的泛化。
一种相似的结构被提出用于处理文本和视觉问答任务,其中视觉输入被送入一个深卷积网络中,高层特征被提取并处理成一个注意力网络的输入序列。
如果我们进一步将 memory 和 query 表示扩展到问答任务之外的领域,基于记忆的注意力技术也被用于方面和观点挖掘,query表示为 aspect prototype;在推荐系统中,用户称为 memory component,items 成为 queries;在主题模型中,从深层网络中提取的潜在主题表示构成了 memory 等。
基于图上注意力
论文可参考《Graph Attention Networks》,在以后的图神经网络的博客中会具体介绍。
基于强化学习的注意力
论文《Reinforced Self-Attention Network: a Hybrid of Hard and Soft Attention for Sequence Modeling》中利用强化学习将soft-attention和hard-attention进行了结合。Soft-attention具有参数少、训练快、可微分的优点,但是会将较小但非零的概率分配给琐碎的元素,这降低了少数真正重要元素的注意力,对于较长的输入序列效果不好。Hard-attention的优点是能处理较长的输入序列,缺点是序列采样耗时较大、不可微分。
论文的motivation是将soft attention和hard attention结合起来,使其保留二者的优点,同时丢弃二者的缺点。具体地说,hard attention用于编码关于上下文依赖的丰富的结构信息,并将长序列修剪成短得多的序列,以便soft attention处理。相反,soft attention被用来提供一个稳定的环境和强烈的award来帮助训练hard attention处理之后的序列。该方法既能提高soft attention的预测质量,又能提高hard attention的可训练性,同时提高了对上下文依赖关系建模的能力。模型的整体框架如下图:
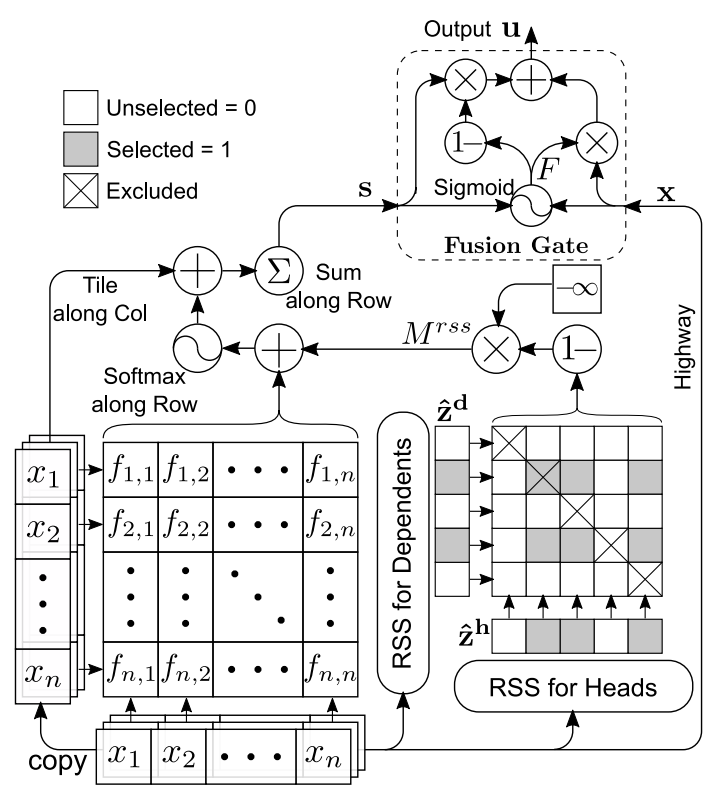
RSS
Hard attention的目标是从输入序列中选择关键的words,这些关键的words能够提供足够的信息来完成下游任务,这样就可以排除掉许多boring words,从而减少模型的训练时间。
给定一个输入序列$\boldsymbol{x}=\left[x_{1}, \ldots, x_{n}\right]$,RSS生成一个等长的向量$\boldsymbol{z}=\left[z_{1}, \ldots, z_{n}\right]$,其中意$z_{i}=1$味着x_i会被选择,而则$z_{i}=0$意味着$x_i$会被忽略掉。在RSS中,$z_i$是通过attention机制计算的结果作为其采样的概率。RSS的目标是学习到以下的分布:$p\left(\boldsymbol{z} \mid \boldsymbol{x} ; \theta_{r}\right)=\prod_{i=1}^{n} p\left(z_{i} \mid \boldsymbol{x} ; \theta_{r}\right)$,其中$p\left(z_{i} \mid \boldsymbol{x} ; \theta_{r}\right)=g\left(f\left(\boldsymbol{x} ; \theta_{f}\right)_{i} ; \theta_{g}\right)$
其中,$f\left(\cdot ; \theta_{f}\right)$表示一个上下文融合层(context fusion layer),如Bi-LSTM,Bi-GRU等,为$x_i$生成一个上下文敏感的representation。$g\left(\cdot ; \theta_{g}\right)$将$f\left(\cdot ; \theta_{f}\right)$映射到$x_i$被选中的概率。注意到$z_i$的计算方式不依赖于$z_{i-1}$,因此这个步骤可以并行完成。为了进一步提高了效率。文章通过下面这个式子来计算$f\left(\cdot ; \theta_{f}\right)$:$f\left(\boldsymbol{x} ; \theta_{f}\right)_{i}=\left[x_{i} ; \text { mead_pooling }(\boldsymbol{x}) ; x_{i} \odot \text { mead_pooling }(\boldsymbol{x})\right]$
而$g\left(f\left(x ; \theta_{f}\right)_{i} ; \theta_{g}\right)$的计算方式则与论文《DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding》相似:
$g\left(f\left(x ; \theta_{f}\right)_{i} ; \theta_{g}\right)=\operatorname{sigmoid}\left(w^{T} \sigma\left(W^{(R)} f\left(x ; \theta_{f}\right)_{i}+b^{(R)}\right)+b\right)$
ReSA
在ReSA中,两个参数独立的RSS分别对输入序列的进行采样,采样结果分别称为head tokens和dependent tokens:
$\hat{z}^{h}=\left[\hat{z}_{1}^{h}, \ldots, \hat{z}_{n}^{h}\right] \sim \operatorname{RSS}\left(x ; \theta_{r h}\right)$
$\hat{z}^{d}=\left[\hat{z}_{1}^{d}, \ldots, \hat{z}_{n}^{d}\right] \sim \operatorname{RSS}\left(x ; \theta_{r d}\right)$
然后使用$\hat{z}^{h} 、 \hat{z}^{d}$生成一个mask:
$M_{i j}^{r s s}=\left\{\begin{array}{ll}
0, & \hat{z}_{i}^{d}=\hat{z}_{j}^{h}=1 \& i \neq j \\
-\infty, & \text { otherwise }
\end{array}\right.$
把$M^{r s s}$放到Masked Self-Attention中:
$f^{r s s}\left(x_{i}, x_{j}\right)=c \cdot \tanh \left(\left[W^{(1)} x_{i}+W^{(2)} x_{j}+b^{(1)}\right] / c\right)+M_{i j}^{r s s}$
$f^{r s s}\left(x_{i}, x_{j}\right)$即score function,然后使用softmax函数计算概率:
$P^{j}=\operatorname{softmax}\left(\left[f^{r s s}\left(x_{i}, x_{j}\right)\right]_{i=1}^{n}\right), \text { for } j=1, \ldots, n$
$x_j$的上下文注意力特性通过以下方式计算:
$s_{j}=\sum_{i=1}^{n} P_{i}^{j} \odot x_{i}, \text { for } j=1, \ldots, n$
最后,使用与DiSAN相同的融合层给出最终的输出:
$F=\operatorname{sigmoid}\left(W^{(f)}[\boldsymbol{x} ; s]+b^{(f)}\right)$
$\boldsymbol{u}=F \odot \boldsymbol{x}+(1-F) \odot \boldsymbol{s}$
Training
使用Policy Gradient方法,让soft先训练,经过冷启动以后再启动hard的强化学习。
多源注意力机制
论文《Multi-Source Neural Translation》使用英语,德语,法语三种语言建立了一种多源机器翻译模型。Martin Kay曾在他关于多语言翻译的文章中提到过,如果一篇文章被翻译成了另一种语言,那么就更加倾向于被翻译成其他语言。这样的观点给在机器翻译任务中给人以启发,将原本的单一源语言替换为多种源语言,应该可以取得更好的效果。如英语中的“bank”一词原本可以翻译为河岸或是银行,如果源语言中有德语词汇“Flussufer”(河岸)作为帮助,则自然可以精确得到法语中“Berge”(河岸)这样的翻译结果。基于这样的思想,作者在原有的seq2seq+attention模型的基础上做了修改,引入更多源语句,建立一种多源的翻译模型。
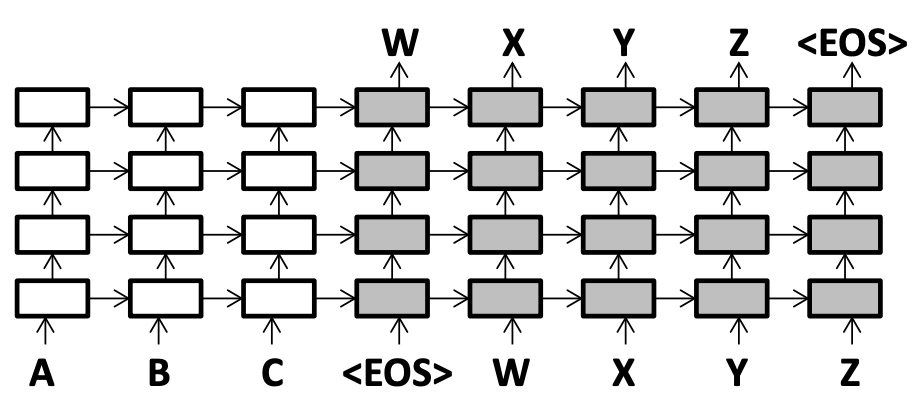
经典的seq2seq翻译模型如下图,在本文中作者采用的四层LSTM作为encoder和decoder,hidden state的维度为1000:
改造后的翻译模型结构如下图,每一个源语言都有自己的一个encoder,并且两个encoder的结构一致。改造之后的关键问题在于如何融合两个encoder的hidden state(h1, h2)和cell state(c1, c2),再将融合好之后的状态送入decoder中解码输出;以及在attention model如何改造能在两个encoder中学习到权重。
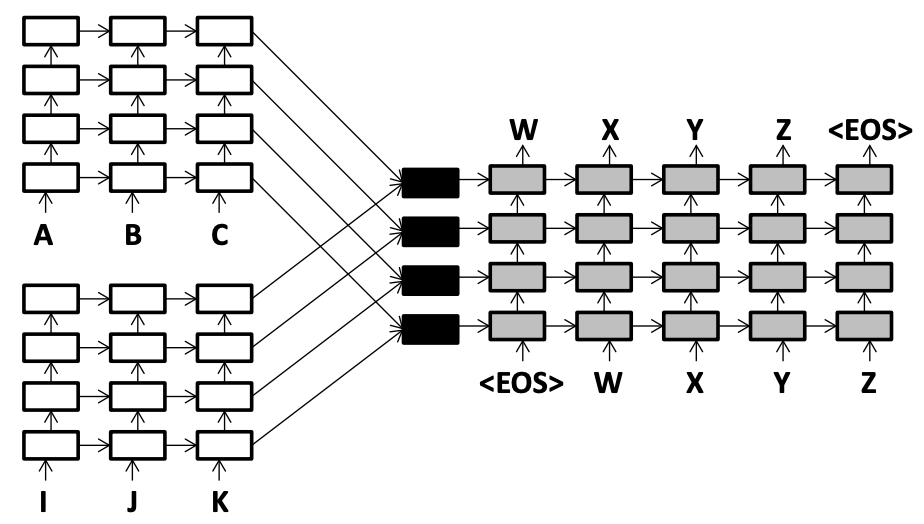
状态融合方法
基本融合法
该方法比较简单粗暴,将两个encoder最后的hidden state直接相连,再经过一个线性变换和激活函数,变换公式为:$h=\tanh \left(W_{c}\left[h_{1} ; h_{2}\right]\right)$,其中矩阵W_c的维度是2000*1000,细胞状态就是简单的相加:$c=c_{1}+c_{2}$。作者在论文中提到也尝试将两个细胞状态做跟隐藏层一样的拼接变换,但是在训练时可能因为细胞的值太大而无法收敛。
Child-Sum Method
第二种融合方法出自Child-SumTree-LSTMs ,采用一个LSTM的变体将两个encoder的状态融合到一起。所有标准的LSTM输入、输出和新的单元值都是经过计算的。然后每个编码器的细胞状态都有自己的遗忘门。最终的细胞状态和隐藏状态在LSTM中被计算出来。计算公式为:
- $i=\operatorname{sigmoid}\left(W_{1}^{i} h_{1}+W_{2}^{i} h_{2}\right)$代表输入门,是1000维的向量
- $f=\operatorname{sigmoid}\left(W_{i}^{f} h_{i}\right)$代表遗忘门,是1000维的向量
- $o=\operatorname{sigmoid}\left(W_{1}^{o} h_{1}+W_{2}^{o} h_{2}\right)$代表输出门,是1000维的向量
- $u=\tanh \left(W_{1}^{u} h_{1}+W_{2}^{u} h_{2}\right)$是1000维的向量
- $c=i_{f} \odot u_{f}+f_{1} \odot c_{1}+f_{2} \odot c_{2}$
- $h=o_{f} \odot \tanh \left(c_{f}\right)
上述公式中新增了8个矩阵,每个矩阵的尺寸都是1000*1000。
多源注意力机制
本文中作为对比试验使用的单源注意力模型采用的是local-p attention model。decoder的隐藏状态可以回顾encoder的所有隐藏状态,从而学得一个更好的隐藏状态。local-p attention model采用如下方式操作:$p_{t}=S \cdot \operatorname{sigmoid}\left(v_{p}^{T} \tanh \left(W_{p} h_{t}\right)\right)$,S是源语句的长度。pt计算完之后用一个尺寸为(2D+1)的窗口在以pt(D=10)为中心的源编码器的顶层中查看。对每一个窗口内的隐层状态,都计算一个0-1之间的对齐分数(权重)at(s)。计算方法如下:
- $a_{t}(s)=\operatorname{align}\left(h_{t}, h_{s}\right) \exp \left(\frac{-\left(s-p_{t}\right)^{2}}{2 \sigma^{2}}\right)$,s是隐藏状态的源索引
- $\operatorname{align}\left(h_{t}, h_{s}\right)=\frac{\exp \left(\operatorname{score}\left(h_{t}, h_{s}\right)\right)}{\sum_{s^{\prime}} \exp \left(\operatorname{score}\left(h_{t}, h_{s^{\prime}}\right)\right)}$
- $\operatorname{score}\left(h_{t}, h_{s}\right)=h_{t}^{T} W_{a} h_{s}$
当所有对齐参数都被计算出来之后,ct是通过求所有源隐藏状态乘以它们的对齐权重的加权总和来创建的。最终送入softmax层的隐层状态为$\tilde{h}_{t}=\tanh \left(W_{c}\left[h_{t} ; c_{t}\right]\right)$。
论文中修改权重模型,同时查看两个源的encoder。为每一个encoder创建一个上下文向量ct1 和ct2(在单源模型中只有ct),即:$\tilde{h_{t}}=\tanh \left(W_{c}\left[h_{t} ; c_{t}^{1} ; c_{t}^{2}\right]\right)$。因此在修改之后的注意力机制模型中有两个pt变量。还有两套不同的对齐参数。还有两个ct值表示为上述的c1t和c2t。
在对话方向上,也有一篇论文《Two are Better than One: An Ensemble of Retrieval- and Generation-Based Dialog Systems》借鉴了该思想,具体思想可参考知乎文章:https://zhuanlan.zhihu.com/p/31277046。
注意力之上的注意力
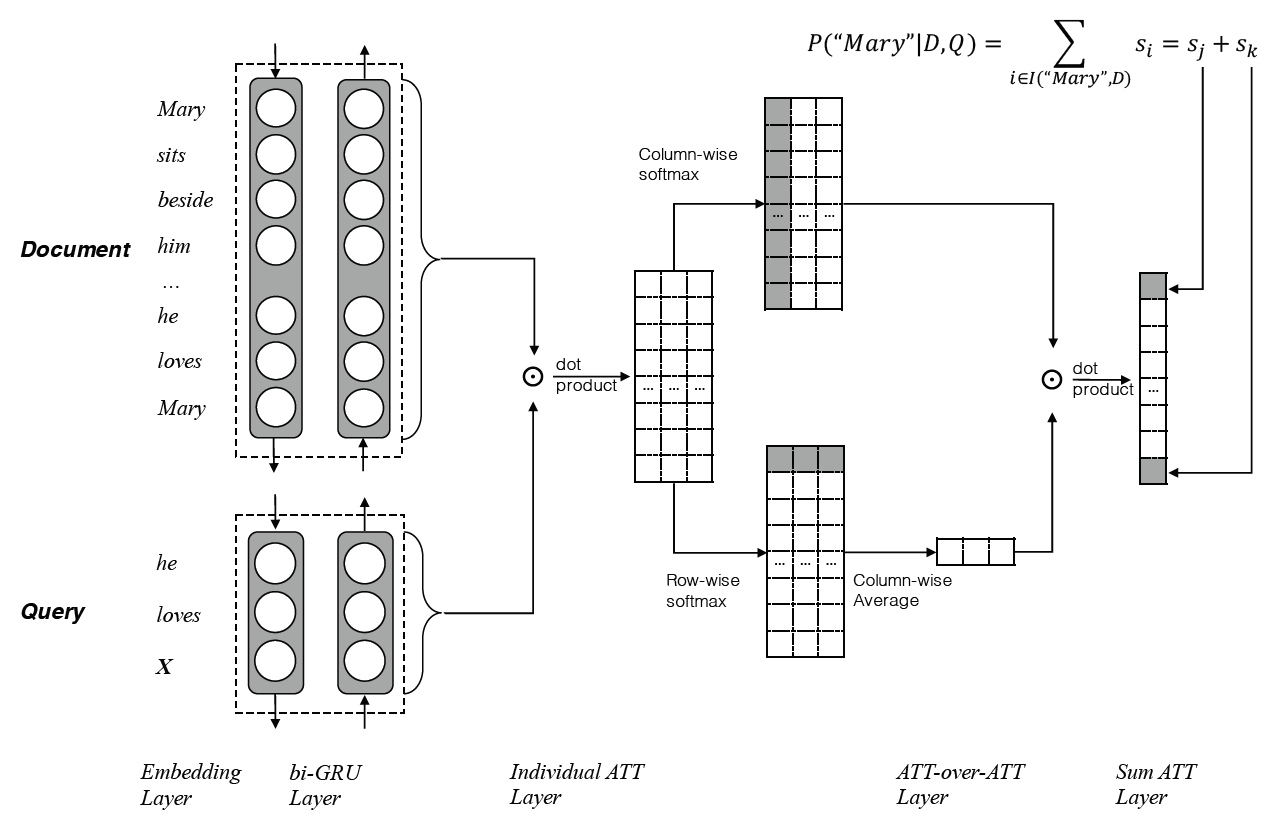
论文《Attention-over-Attention Neural Networks for Reading Comprehension》使用一种新颖的模式解决了完形填空式阅读理解任务。其具体过程如下:
- 获取document hdoc和query hquery的文本嵌入
- 把document D和query Q中的每个单词都转换为一个one-hot表示
- 用一个共享嵌入矩阵We把它们转换为连续表示$e(x)=W_{e} \cdot x, \text { where } x \in \mathcal{D}, \mathcal{Q}$
- 使用两个双向rnn来获取query和document的文本表示,其中每一个词的表达都是通过前向和后向隐藏层的拼接,使用GRU来作为使用的循环单元
- $\overrightarrow{h_{s}(x)}=\overrightarrow{G R U}(e(x))$
- $\overleftarrow{h_{s}(x)}=\overleftarrow{G R U}(e(x))$
- $h_{s}(x)=\left[\overrightarrow{h_{s}(x)} ; \overleftarrow{h_{s}(x)}\right]$
- $h_{d o c} \in \mathbb{R}^{|\mathcal{D}| * 2 d}$
- $h_{q u e r y} \in \mathbb{R}|\mathcal{Q}| * 2 d$
- 计算pair-wise匹配矩阵:$M(i, j)=h_{d o c}(i)^{T} \cdot h_{q u e r y}(j)$表示document的第i个词和query的第j个词的匹配分数,依据这个分数可以构造矩阵$M \in \mathbb{R}^{|\mathcal{D}| * \mid \mathcal{Q}}$
- 计算query-to-document attention:应用一个column-wise的softmax函数来得到了每一列的概率分布,每一列都是考虑一个query词的document的attention分布。我们把时间t(query)处的document attention分布称作$\alpha(t) \in \mathbb{R}^{|\mathcal{D}|}$,其中$\alpha(t)=\operatorname{softmax}(M(1, t), \ldots, M(|\mathcal{D}|, t))$,$\alpha=[\alpha(1), \alpha(2), \ldots, \alpha(|\mathcal{Q}|)]$
- 计算document-to-query attention:用一个row-wise softmax函数来对pair-wise匹配矩阵M来得到query级别的attention,对于一个在时间t的document词,我们计算query中每个词对他的重要性分布,来表明query中哪个词对这个document词更加重要。把时间t(document)处的query attention分布称作$\beta(t) \in \mathbb{R}^{|\mathcal{Q}|}$,其中$\beta(t)=\operatorname{softmax}(M(t, 1), \ldots, M(t,|\mathcal{Q}|))$
- 计算document和query的交互信息
- 平均所有的β(t)来得到一个平均的query上的attention β:$\beta=\frac{1}{n} \sum_{t=1}^{|\mathcal{D}|} \beta(t)$
- 计算α和β之间的点积:$s=\alpha^{T} \beta$,$s \in \mathbb{R}^{|\mathcal{D}|}$这个操作就是看着query的词汇t的时候,计算所有document单体attention的加权和。这样,每一个query词汇的贡献度就能直接学习到。
- 预测结果:用sum attention mechanism 方法来聚合结果。注意最后的输出应该被reflected 到词汇空间V,而不是document级别的attention |D|,这会在性能上引起很大差异:$P(w \mid \mathcal{D}, \mathcal{Q})=\sum_{i \in I(w, \mathcal{D})} s_{i}, w \in V$
- 其中I(w,D)表示词汇w出现在document中的位置的集合。
- 作为训练目标,我们最大化正确答案的log函数:$\mathcal{L}=\sum_{i} \log (p(x)), x \in \mathcal{A}$
整体计算过程如下图所示:
多跳注意力机制
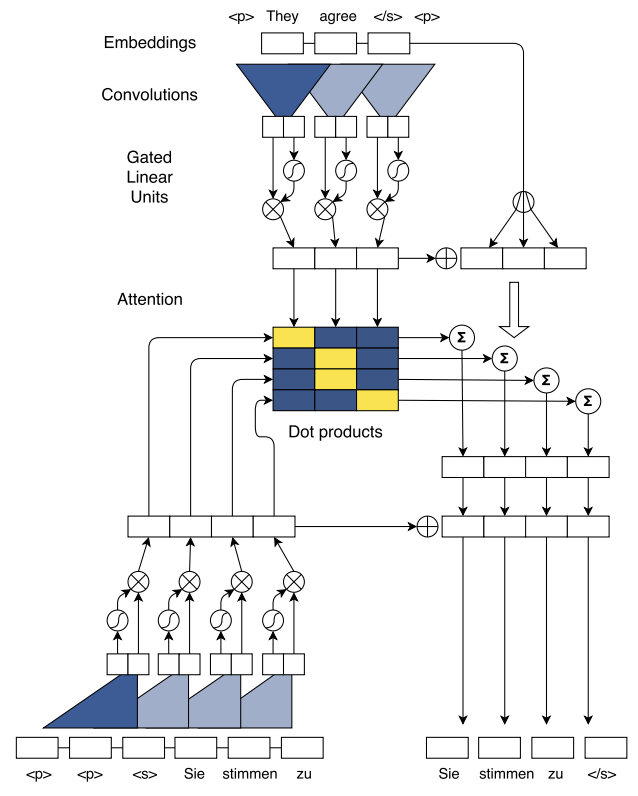
论文《Convolutional Sequence to Sequence Learning》使用encoder-decoder + attention模块的大框架来处理机器翻译的任务:encoder 和 decoder采用了相同的卷积结构,其中的非线性部分采用的是门控结构 gated linear units(GLM);attention 部分采用的是多跳注意 multi-hop attention,也即在 decoder 的每一个卷积层都会进行 attention 操作,并将结果输入到下一层。其具体过程如下:
- Position Embeddings
- 词向量:$w=\left(w_{1}, \ldots, w_{n}\right)$
- 位置向量:$p=\left(p_{1}, \ldots, p_{n}\right)$
- 最终表示向量:$e=\left(w_{1}+p_{1}, \ldots, w_{n}+p_{n}\right)$
- Convolutional Block Structure
- encoder 和 decoder 都是由 l 层卷积层构成,encoder输出为 $z^l $,decoder输出为 $h^l$,由于卷积网络是层级结构,通过层级叠加能够得到远距离的两个词之间的关系信息
- 卷积计算:卷积核的大小为$W \in \mathbb{R}^{2 d \times k d}$,其中d为词向量长度,k为卷积窗口大小,每次卷积生成两列d维向量$Y=[A B] \in \mathbb{R}^{2 d}$
- 非线性计算:非线性部分采用的是门控结构 gated linear units(GLM),即$v([A, B])=A \otimes \delta(B)$,其中$\delta(B)$是门控函数,控制着网络中的信息流,即哪些能够传递到下一个神经元中。
- 残差连接:$h_{i}^{l}=v\left(W^{l}\left[h_{i-k / 2}^{l-1}, \ldots, h_{i+k / 2}^{l-1}\right]+b^{l}\right)+h_{i}^{l-1}$
- Decoder输出:$p\left(y_{i+1} \mid y_{1}, \ldots, y_{i}, x\right)=\operatorname{softmax}\left(W_{o} h_{i}^{L}+b_{o}\right)$
- Multi-step Attention
- $d_{i}^{l}=W_{d}^{l} h_{i}^{l}+b_{d}^{l}+g_{i}$
- $a_{i j}^{l}=\frac{\exp \left(d_{i}^{l} \cdot z_{j}^{u}\right)}{\sum_{t=1}^{m} \exp \left(d_{i}^{l} \cdot z_{t}^{u}\right)}$为权重信息,采用了向量点积的方式再进行softmax操作,这里向量点积可以通过矩阵计算,实现并行计算
- $c_{i}^{l}=\sum_{j=1}^{m} a_{i j}^{l}\left(z_{j}^{u}+e_{j}\right)$
- $h_i = c_i + h_i$每一个卷积层都会进行 attention 的操作,得到的结果输入到下一层卷积层,这就是多跳注意机制multi-hop attention。这样做的好处是使得模型在得到下一个主意时,能够考虑到之前的已经注意过的词。
模型的整体结构如下图:
多维度注意力
DiSAN
论文《DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding》创新性地提出了 2 种 attention mechanism: multi-dimensional attention 和 directional attention。 前者用矩阵代替向量来表示 attention weights, 将加权求和细化到状态向量的每一维; 后者通过 Mask 矩阵将方向编码进 attention, 解决了时序丢失问题. 基于两种 attention提出了 Directional Self-Attention Network, DiSAN 模型, 在不依赖 RNN/CNN 的情况下, 在多项任务 NLP 任务上取得了 SOTA 的成绩.
Multi-Dimensional Attention
普通 attention 的 alignment score 是一个标量即$f\left(x_{i}, q\right)=w^{T} \sigma\left(W^{(1)} x_{i}+W^{(2)} q\right)$,之后、$a=\left[f\left(x_{i}, q\right)\right]_{i=1}^{n}$、$p(z \mid \boldsymbol{x}, q)=\operatorname{softmax}(a)$得到的 attention weight p_i也是一个标量, 最后计算输出状态$s=\sum_{i=1}^{n} p(z=i \mid \boldsymbol{x}, q) x_{i}=\mathbb{E}_{i \sim p(z \mid \boldsymbol{x}, q)}\left(x_{i}\right)$,$s \in \mathbb{R}^{d_{e}}$是句子表示。
Multi-dimensional attention 的依据是x_k的每一位数字都是一个特征 (比如 king 的词向量, 某一位数字表征性别, 某一位数字表征尊贵程度), 可以拥有自己的 attention weight, 文中称为 feature-wise attention. 具体做法就是将上面 f 函数中的权值向量替换为权值矩阵:
$f\left(x_{i}, q\right)=W^{T} \sigma\left(W^{(1)} x_{i}+W^{(2)} q+b^{(1)}\right)+b$
如此得到的$z_i$将是与$x_i$具有相同 embedding dimension 的向量, 该向量的每一位数字表征$x_i$与 q 相应位置上的对齐程度。 后续的计算过程与上总体无异, 只是 z 成了矩阵, softmax 应用于 z 的第二维,如下图(b):
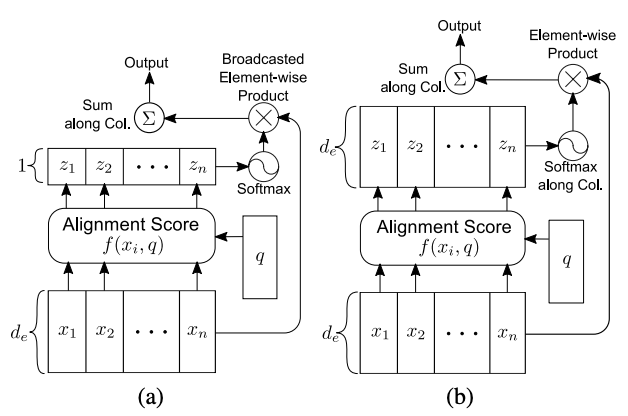
Multi-dimensional attention 对于同一个 token embedding 的不同 feature 计算不同的 attention weight, 充分利用了上下文与 token 不同特征之间的对齐程度. 还是以 king 为例, 当上下文强调性别属性时, 性别特征将得到更大的 attention weight, 而尊贵程度不那么重要, 可能就只分配很小的 attention weight。 对于一词多义的情况, multi-dimensional attention 还具有一定的消除歧义作用。
在 multi-dimensional attention 的基础上, 文章得到了 2 个 self-attention 变种, 两者的差别在于 query:
token2token: 计算序列中两个位置的依赖程度 (对于 self-attention, 依赖的说法比对齐更合适), 此时只需将外部 query q 替换为序列中另一个位置的状态即可(由于需要计算位置两两之间的对齐程度, token2token 的输出是一个矩阵):$f\left(x_{i}, x_{j}\right)=W^{T} \sigma\left(W^{(1)} x_{i}+W^{(2)} x_{j}+b^{(1)}\right)+b$
source2token: 计算序列某位置状态与整个序列的对齐程度, 文章简单地将 query 剔除了(source2token 的 输出是向量):$f\left(x_{i}\right)=W^{T} \sigma\left(W^{(1)} x_{i}+b^{(1)}\right)+b$
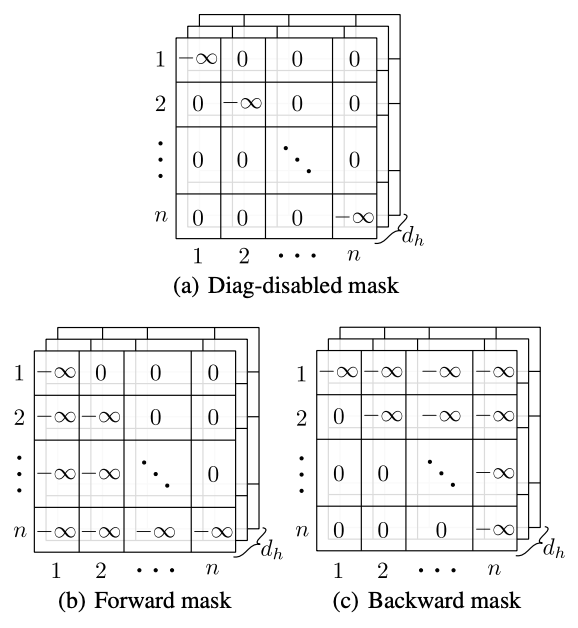
Directional Self-Attention
Directional self-attention (DiSA) 由一个全连阶层 FC, 一个 masked multi-dimensional token2token self-attention block, 一个 fusion gate 组成:
- FC 将输入序列转换成隐藏状态的序列
- multi-dimensional token2token self-attention 学习各隐藏状态之间的关系, 并使用 Mask 将方向编码进结果
- 通过 mask 矩阵, 实现了非对称依赖, 即h_j对h_i有依赖, 反之却没有, 从而实现了方向性
- Mask 是一个非零即负无穷的方阵, 因为负无穷的指数为0,从而能抑制依赖关系
- 上式可修改为$\begin{array}{l}
f\left(h_{i}, h_{j}\right)= \\
c \cdot \tanh \left(\left[W^{(1)} h_{i}+W^{(2)} h_{j}+b^{(1)}\right] / c\right)+M_{i j} \mathbf{1}
\end{array}$ - 文中使用了 forward mask 与 backward mask, 前者的作用是使得只存在后面状态对前面状态的依赖;,后者则恰好相反:
- fusion gate 是一个门控单元, 控制 DiSA 中 FC 的输出与 token2token 输出的比例
- Fusion gate 是 dimension-wise 的, 即全面控制输出结果向量的每一位数字
- $F=\operatorname{sigmoid}\left(W^{(f 1)} s+W^{(f 2)} \boldsymbol{h}+b^{(f)}\right)$
- $\boldsymbol{u}=F \odot \boldsymbol{h}+(1-F) \odot \boldsymbol{s}$
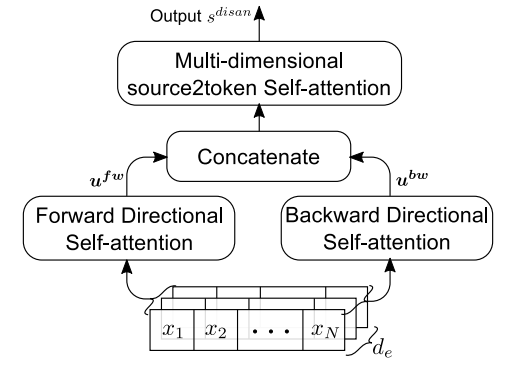
最终, DiSAN 由两个 DiSA blocks 和一个 multi-dimensional source2token self-attention layer 组成. 通过 DiSA 分别对前向与反向 上下文依赖 context dependency 进行建模, 为每一个 token 生成一个上下文感知 context-aware 的表示; 然后用 source2token 计算整个序列的向量表示:
基于拷贝机制的注意力
PtrNet
论文《Pointer Networks》提出了一种新的指针网络,它主要解决的是Seq2Seq Decoder端输出的词汇表大小不可变的问题。换句话说,传统的Seq2Seq无法解决输出序列的词汇表会随着输入序列长度的改变而改变的那些问题,而某些问题的输出可能会严重依赖于输入。
我们已经知道,Seq2Seq的出现很好地解开了以往的RNN模型要求输入与输出长度相等的约束,而其后的Attention机制(content-based)又很好地解决了长输入序列表示不充分的问题。尽管如此,这些模型仍旧要求输出的词汇表需要事先指定大小,因为在softmax层中,词汇表的长度会直接影响到模型的训练和运行速度,因此人们往往会丢弃生词,保留高频词。之前也有人采用过一些简单的trick解决生词问题,但都不如Copy机制那么有效。下图是PtrNet结构:
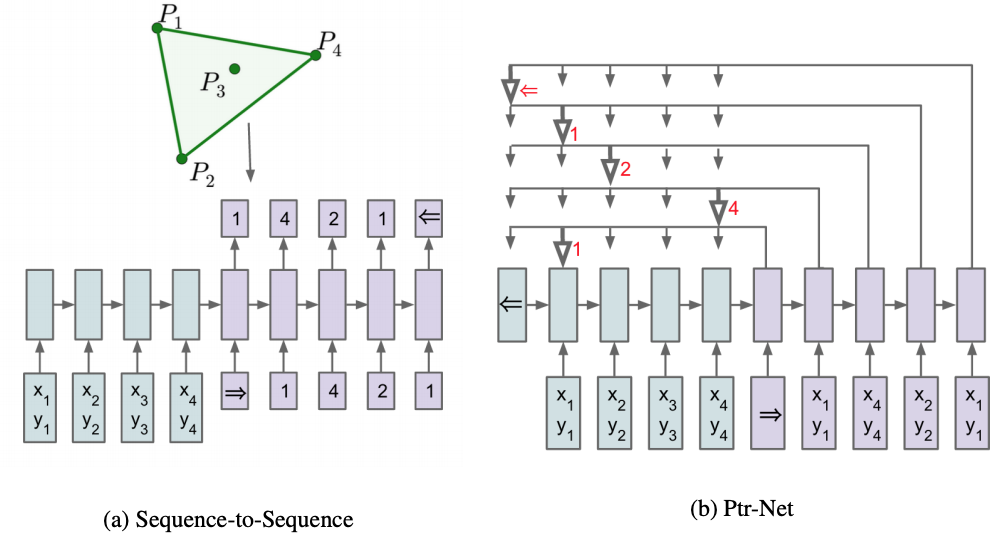
不难想象,Seq2Seq需要词汇表固定的原因是在预测输出时,模型采用了Softmax distribution来计算生成词汇表中每一个词的似然概率,而对于这里的几何问题来说,输出集合是与输入相关联的,为了解决这个问题,作者将Attention机制改为了如下形式:
- $u_{j}^{i}=v^{T} \tanh \left(W_{1} e_{j}+W_{2} d_{i}\right) \quad j \in(1, \ldots, n)$
- $p\left(C_{i} \mid C_{1}, \ldots, C_{i-1}, \mathcal{P}\right)=\operatorname{softmax}\left(u^{i}\right)$
第一个式子和Attention一样,即计算当前输出与对应输入之间的相关性分数,然后对其进行softmax归一化得到权重,在这里,PrtNets直接将权重最大的输入(也就是所谓指针指向的输入)作为输出,也就是直接copy注意力得分最高的输入作为输出。实际上,传统的带有注意力机制的Seq2Seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。虽然简单,但十分有用,由于输出元素来自输入元素的特点,PtrNets特别适合用来直接复制输入序列中的某些元素给输出序列。这对于那些输出为输入的position的任务非常有效。
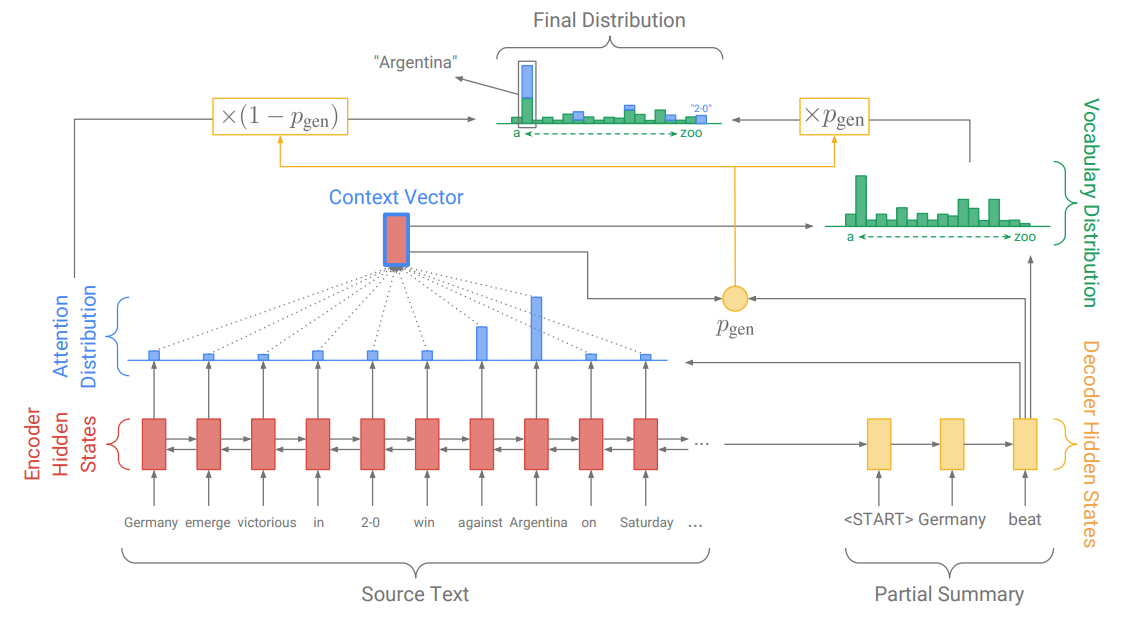
论文《Get To The Point: Summarization with Pointer-Generator Networks》融合了seq2seq模型和pointer network的pointer-generator network以及覆盖率机制(coverage mechanism)应用于摘要生成。模型主要框架如下:
我们知道,对于普通的seq2seq模型的attention计算公式为:
- $e_{i}^{t}=v^{T} \tanh \left(W_{h} h_{i}+W_{s} s_{t}+b_{\mathrm{attn}}\right)$,$h_i$是输出的编码隐层状态,$s_t$是解码的隐层状态
- $a^{t}=\operatorname{softmax}\left(e^{t}\right)$
- $h_{t}^{*}=\sum_{i} a_{i}^{t} h_{i}$对encoder输出的隐层做加权平均,获得原文的动态表示,称为语境向量
- $P_{\text {vocab }}=\operatorname{softmax}\left(V^{\prime}\left(V\left[s_{t}, h_{t}^{*}\right]+b\right)+b^{\prime}\right)$依靠decoder输出的隐层和语境向量,共同决定当前步预测在词表上的概率分布
- $P(w)=P_{\text {vocab }}(w)$
- $\operatorname{loss}_{t}=-\log P\left(w_{t}^{*}\right)$
Pointer-generator network是seq2seq模型和pointer network的混合模型,一方面通过seq2seq模型保持抽象生成的能力,另一方面通过pointer network直接从原文中取词,提高摘要的准确度和缓解OOV问题。在预测的每一步,通过动态计算一个生成概率$p_{gen}$,把二者软性地结合起来:$p_{\text {gen }}=\sigma\left(w_{h^{}}^{T} h_{t}^{}+w_{s}^{T} s_{t}+w_{x}^{T} x_{t}+b_{\mathrm{ptr}}\right)$
文章对pointer network的处理比较巧妙,直接把seq2seq模型计算的attention分布作为pointer network的输出,通过参数复用,大大降低了模型的复杂度,最终的预测为:$P(w)=p_{\text {gen }} P_{\text {vocab }}(w)+\left(1-p_{\text {gen }}\right) \sum_{i: w_{i}=w} a_{i}^{t}$
论文额外还增加了一个coverage向量$c^{t}=\sum_{t^{\prime}=0}^{t-1} a^{t^{\prime}}$计算过去所有预测步计算的attention分布的累加和,记录着模型已经关注过原文的哪些词,并且让这个coverage向量影响当前步的attention计算:$e_{i}^{t}=v^{T} \tanh \left(W_{h} h_{i}+W_{s} s_{t}+w_{c} c_{i}^{t}+b_{\mathrm{attn}}\right)$。这样做的目的在于,在模型进行当前步attention计算的时候,告诉它之前它已经关注过的词,希望避免出现连续attention到某几个词上的情形。同时,coverage模型还添加一个额外的coverage loss,来对重复的attention作惩罚:$\text { covloss }_{t}=\sum_{i} \min \left(a_{i}^{t}, c_{i}^{t}\right)$。值得注意的是这个loss只会对重复的attention产生惩罚,并不会强制要求模型关注原文中的每一个词。最终,模型的整体损失函数为:$\operatorname{loss}_{t}=-\log P\left(w_{t}^{*}\right)+\lambda \sum_{i} \min \left(a_{i}^{t}, c_{i}^{t}\right)$。不过文章在实验部分提到,如何移除了covloss,单纯依靠coverage向量去影响attention的计算并不能缓解重复问题,模型还是会重复地attention到某些词上。而加上covloss的模型训练上也比较trick,需要先用主函数训练好一个收敛的模型,然后再把covloss加上,做个finetune,不然的话效果还是不好。
CopyNet
论文《Incorporating Copying Mechanism in Sequence-to-Sequence Learning》提出了CopyNet,在 Seq2Seq + Attention 的基础上,引入了拷贝机制,模型结构如下图:
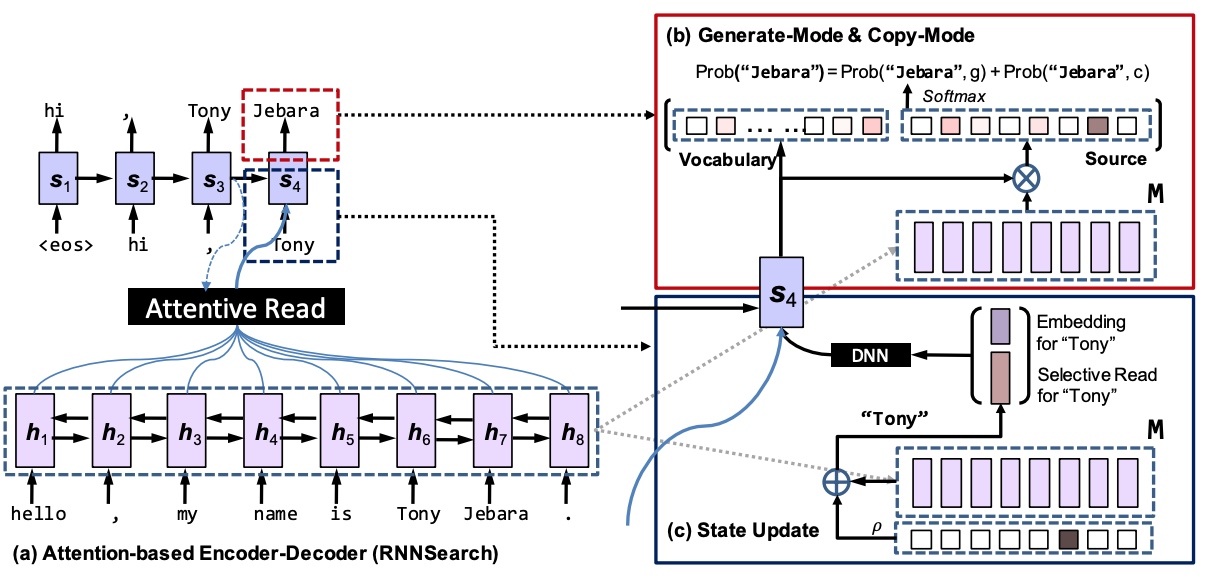
一般的encoder-decoder结构和基于attention的encoder-decoder结构都严重依赖于input的表征,很难处理output中需要copy input中一些实体名字的问题。本文提出的COPYNET就可以兼顾表征和copy。还有个问题就是,copy这个操作是一个0-1操作,意思就是选择copy时是1,不选择copy是0,这种硬选择很难优化,本文还是用end-end的网络进行了训练。模型的具体计算过程如下:
- encoder:bi-directional RNN 得到source sentence的定长hidden states。每个h_t 对应一个source word $x_t$,source sentence的表征就变成了 $\{h_1, …, h_{T_s}\}$ (文中用符号M表示)
- decoder:把M输入到RNN中,预测target sequence。
- Prediction:从decoder hidden state s_t到预测输出y_t的过程,本来是一个线性映射就可以,现在要用generate-mode和copy-mode的混合概率预测:$p\left(y_{t} \mid s_{t}, y_{t-1}, c_{t}, M\right)=p\left(y_{t}, g \mid s_{t}, y_{t-1}, c_{t}, M\right)+p\left(y_{t}, c \mid s_{t}, y_{t-1}, c_{t}, M\right)$
- Generate-Mode:对输出词表$\mathcal{V}=\left\{v_{1}, \ldots v_{N}\right\}$中的单词$v_i$(one-hot表示),未登录词UNK,输入词$\mathcal{X}$有:
- $\psi_{g}\left(y_{t}=v_{i}\right)=\mathbf{v}_{i}^{\top} \mathbf{W}_{o} \mathbf{s}_{t}, \quad v_{i} \in \mathcal{V} \cup \mathrm{UNK}$,其中$\mathbf{W}_{o} \in \mathbb{R}^{(N+1) \times d_{s}}$
- $p\left(y_{t}, \mathrm{~g} \mid \cdot\right)=\left\{\begin{array}{cc}
\frac{1}{Z} e^{\psi_{g}\left(y_{t}\right)}, & y_{t} \in \mathcal{V} \\
0, & y_{t} \in \mathcal{X} \cap \bar{V} \\
\frac{1}{Z} e^{\psi_{g}(\mathrm{UNK})} & y_{t} \notin \mathcal{V} \cup \mathcal{X}
\end{array}\right.$ - $Z=\sum_{v \in \mathcal{V} \cup\{U N K\}} e^{\psi_{g}(v)}+\sum_{x \in X} e^{\psi_{c}(x)}$
- Copy-Mode:论文模型不仅基于内容(the content),也基于句子的信息位置(location information),因此当计算得分函数时,用$\{h_1, …, h_{T_S}\}$来替代源句子$\{x_1, …, x_{T_S}\}$,因此对输入中出现的单词$\mathcal{X}$有:
- $\psi_{c}\left(y_{t}=x_{j}\right)=\sigma\left(\mathbf{h}_{j}^{\top} \mathbf{W}_{c}\right) \mathbf{s}_{t}, \quad x_{j} \in \mathcal{X}$,其中$\mathbf{W}_{c} \in \mathbb{R}^{d_{h} \times d_{s}}$,$d_h$、$d_s$是$h_j$、$s_t$的维度
- $p\left(y_{t}, \mathrm{c} \mid \cdot\right)=\left\{\begin{array}{cc}
\frac{1}{Z} \sum_{j: x_{j}=y_{t}} e^{\psi_{c}\left(x_{j}\right)}, & y_{t} \in \mathcal{X} \\
0 & \text { otherwise }
\end{array}\right.$
- Generate-Mode:对输出词表$\mathcal{V}=\left\{v_{1}, \ldots v_{N}\right\}$中的单词$v_i$(one-hot表示),未登录词UNK,输入词$\mathcal{X}$有:
- State Update:对于seq2seq中的Attention,发生在更新$s_t$上,即$\mathbf{s}_{t}=f\left(y_{t-1}, \mathbf{s}_{t-1}, \mathbf{c}_{t}\right)$其中$c_t$是context vector,也就是attention模块,其计算公式如下:$\mathbf{c}_{t}=\sum_{\tau=1}^{T_{S}} \alpha_{t \tau} \mathbf{h}_{\tau}, \quad \alpha_{t \tau}=\frac{e^{\eta\left(\mathbf{s}_{t-1}, \mathbf{h}_{\tau}\right)}}{\sum_{\tau^{\prime}} e^{\eta\left(\mathbf{s}_{t-1}, \mathbf{h}_{\tau^{\prime}}\right)}}$,CopyNet的$y_{t-1}$在这里有些不同,这里被表示成了$\left[\mathbf{e}\left(y_{t-1}\right) ; \zeta\left(y_{t-1}\right)\right]^{\top}$,前一项是word embedding,多一项的后一项叫做selective read,是为了能连续拷贝较长的短语:
- $\zeta\left(y_{t-1}\right)=\sum_{\tau=1}^{T_{S}} \rho_{t \tau} \mathbf{h}_{\tau}$表示M中和$y_t$对应的hidden states加权
- $\rho_{t \tau}=\left\{\begin{array}{cc}
\frac{1}{K} p\left(x_{\tau}, \mathbf{c} \mid \mathbf{s}_{t-1}, \mathbf{M}\right), & x_{\tau}=y_{t-1} \\
0 & \text { otherwise }
\end{array}\right.$,K类似softmax的分母,因为$y_{t-1}$可能会出现在source sequence中的多个位置,实际中总$\rho_{t \tau}$是只关心其中一个
- Reading M:除了添加注意力机制外,还添加了选择机制。相当于content-based addressing 和location-based addressing的混合。
- Location-based Addressing:利用{$h_i$}中的位置信息,X每向右移动一步,产生的信息流动为$\zeta\left(y_{t-1}\right) \stackrel{\text { update }}{\longrightarrow} s_{t} \stackrel{\text { predict }}{\longrightarrow} y_{t} \stackrel{\text { sel.read }}{\longrightarrow} \zeta\left(y_{t}\right)$
- Handing Out-of-Vocabulary Words:因为对于OOV的词,是没有embedding来表示其语义信息的。直接copy的话可以利用很多在source中的OOV词。
- Prediction:从decoder hidden state s_t到预测输出y_t的过程,本来是一个线性映射就可以,现在要用generate-mode和copy-mode的混合概率预测:$p\left(y_{t} \mid s_{t}, y_{t-1}, c_{t}, M\right)=p\left(y_{t}, g \mid s_{t}, y_{t-1}, c_{t}, M\right)+p\left(y_{t}, c \mid s_{t}, y_{t-1}, c_{t}, M\right)$
特定任务注意力
论文《Multilingual Neural Machine Translation with Task-Specific Attention》使用特定任务注意力机制进行多语言机器翻译,通过在训练语料中增加语言方向标志,在训练和解码中动态使用相应语言标志的注意力参数。
注意力机制应用
注意力机制可以应用于机器翻译、关系抽取、自然语言推理、对话生成、文本匹配、机器阅读理解(《Text Understanding with the Attention Sum Reader Network 》)、自动摘要(《A Deep Reinforced Model for Abstractive Summarization》)等中。下面以一个自然语言推理的应用为例进行介绍。
自然语言推理
在论文《A Decomposable Attention Model for Natural Language Inference》中也使用了self-attention。传统的自然语言推理大都采用RNN或者CNN来进行句子或者字词特征的提取,而这些网络大都参数较多,并且RNN无法实现并行计算导致计算缓慢。作者这里采用attention的方法,将两个句子的关系问题转化为两个句子对应字词的关系上。由于只采用了几个不同的全连接网络以及attention,所以模型参数较少且可以进行并行计算。模型结构如下:

计算过程如下:
- 每个训练数据由三个部分组成$\left\{a^{(n)}, b^{(n)}, y^{(n)}\right\}_{n=1}^{N}$,模型的输入为$a=\left(a_{1}, \ldots, a_{l_{a}}\right)$、分$b=\left(b_{1}, \ldots, b_{l_{b}}\right)$别代表前提和假说,$y^{n}=\left(y_{1}^{(n)}, \ldots, y_{C}^{(n)}\right)$表示a和b之间的关系标签,C为输出类别的个数,因此y是个C维的0,1向量。训练目标就是根据输入的a和b正确预测出他们的关系标签y。
- Input Representation:原始版本的就是采用预训练好的词向量作为输入的表示,但是由于整个模型只采用了attention机制,所以就没有任何的文本位置信息在里面。所以论文又加了一个intra-sentence attention来得到位置信息:
- $f_{i j}:=F_{\text {intra }}\left(a_{i}\right)^{T} F_{\text {intra }}\left(a_{j}\right)$:$F_{intra}$是一个前馈神经网络
- $a_{i}^{\prime}:=\sum_{j=1}^{\ell_{a}} \frac{\exp \left(f_{i j}+d_{i-j}\right)}{\sum_{k=1}^{\ell_{a}} \exp \left(f_{i k}+d_{i-k}\right)} a_{j}$:$d_{i-j}$表示当前词i与句子中的其他词j之间的距离偏差,距离大于10的词共享一个距离偏差(distance-sensitive bias)
- 每一个时刻的输入就变为原始输入跟self-attention后的值的拼接所得到的向量:$\bar{a}_{i}:=\left[a_{i}, a_{i}^{\prime}\right], \bar{b}_{i}:=\left[b_{i}, b_{i}^{\prime}\right]$
- 可能加入transformer中的position embedding会有同样的效果
- Attend
- a和b中的每个词计算它们之间的attention weights $e_{i j}:=F^{\prime}\left(\bar{a}_{i}, \bar{b}_{j}\right):=F\left(\bar{a}_{i}\right)^{T} F\left(\bar{b}_{j}\right)$
- $a_i$和$b_j$分别代表的是句子a和b中的每个词
- F是一个激活函数为RELU的前馈神经网络
- 假设句子a和句子b的长度分别为 $l_a$ 和 $l_b$ ,如果采用F(a, b)这种计算方式,那个使用F这个方法的次数就是$l_{a} \times l_{b}$,而论文在这里采用$F(a)^TF(b)$的方式,就让计算量变为了$l_{a} \oplus l_{b}$
- 用这个attention weights分别对a和b进行归一化以及加权
- $\beta_{i}:=\sum_{j=1}^{\ell_{b}} \frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{\ell_{b}} \exp \left(e_{i k}\right)} \bar{b}_{j}$
- $\alpha_{j}:=\sum_{i=1}^{\ell_{a}} \frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{\ell_{a}} \exp \left(e_{k j}\right)} \bar{a}_{i}$
- $\beta_{i}$其实就是所有b中的词对于句子a中i位置的加权求和,权重就是之前计算的attention matrix
- a和b中的每个词计算它们之间的attention weights $e_{i j}:=F^{\prime}\left(\bar{a}_{i}, \bar{b}_{j}\right):=F\left(\bar{a}_{i}\right)^{T} F\left(\bar{b}_{j}\right)$
- Compare:该模块的功能主要是对加权后的一个句子与另一个原始句子进行比较
- $\mathbf{v}_{1, i}:=G\left(\left[\bar{a}_{i}, \beta_{i}\right]\right) \quad \forall i \in\left[1, \ldots, \ell_{a}\right]$
- $\mathbf{v}_{2, j}:=G\left(\left[\bar{b}_{j}, \alpha_{j}\right]\right) \quad \forall j \in\left[1, \ldots, \ell_{b}\right]$
- 这里[.,.]表示向量拼接,G()是一个前馈神经网络
- Aggregate
- 先对两个句子集合求和:$\mathbf{v}_{1}=\sum_{i=1}^{\ell_{a}} \mathbf{v}_{1, i}$、$\mathbf{v}_{2}=\sum_{j=1}^{\ell_{b}} \mathbf{v}_{2, j}$
- 将求和的结果输入前馈神经网络做最后的分类:$\hat{\mathbf{y}}=H\left(\left[\mathbf{v}_{1}, \mathbf{v}_{2}\right]\right)$
- 用多分类的交叉熵作为损失函数:$L\left(\theta_{F}, \theta_{G}, \theta_{H}\right)=\frac{1}{N} \sum_{n=1}^{N} \sum_{c=1}^{C} y_{c}^{(n)} \log \frac{\exp \left(\hat{y}_{c}\right)}{\sum_{c^{\prime}=1}^{C} \exp \left(\hat{y}_{c^{\prime}}\right)}$